Table of Contents
[TOC]
数据库排行
事务
跨源
数据虚拟化(data virtualization)是用来描述所有数据管理方法的涵盖性术语,这些方法允许应用程序检索并管理数据,且不需要数据相关的技术细节。
-
阿里云的 【数据管理 DMS】通过 DBLink 实现 跨数据库查询
-
SparkSQL
-
华为的数据虚拟化引擎OpenLookeng
openLooKeng 不是为处理联机事务处理(OLTP)而设计,openLooKeng 被设计用来处理数据仓库和分析:数据分析、聚合大量数据并生成报告。这些工作负载通常归类为联机分析处理(OLAP)。 -
SQL Server 数据虚拟化 (Polybase) 配置 PolyBase 以访问 Hadoop 中的外部数据
-
PostgreSQL 外部数据源支持(Foreign Data Wrapper,FDW)
可以把 70 种外部数据源 (包括 Mysql, Oracle, CSV, hadoop …) 当成自己数据库中的表来查询。Postgres 有一个针对这一难题的解决方案:一个名为“外部数据封装器(Foreign Data Wrapper,FDW)”的特性。该特性最初由 PostgreSQL 社区领袖 Dave Page 四年前根据 SQL 标准 SQL/MED(SQL Management of External Data)开发。FDW 提供了一个 SQL 接口,用于访问远程数据存储中的远程大数据对象,使 DBA 可以整合来自不相关数据源的数据,将它们存入 Postgres 数据库中的一个公共模型。这样,DBA 就可以访问和操作其它系统管理的数据,就像在本地 Postgres 表中一样。例如,使用 FDW for MongoDB,数据库管理员可以查询来自文档数据库的数据,并使用 SQL 将它与来自本地 Postgres 表的数据相关联。借助这种方法,用户可以将数据作为行、列或 JSON 文档进行查看、排序和分组。他们甚至可以直接从 Postgres 向源文档数据库写入(插入、更细或删除)数据,就像一个一体的无缝部署。也可以对 Hadoop 集群或 MySQL 部署做同样的事。FDW 使 Postgres 可以充当企业的中央联合数据库或“Hub”。
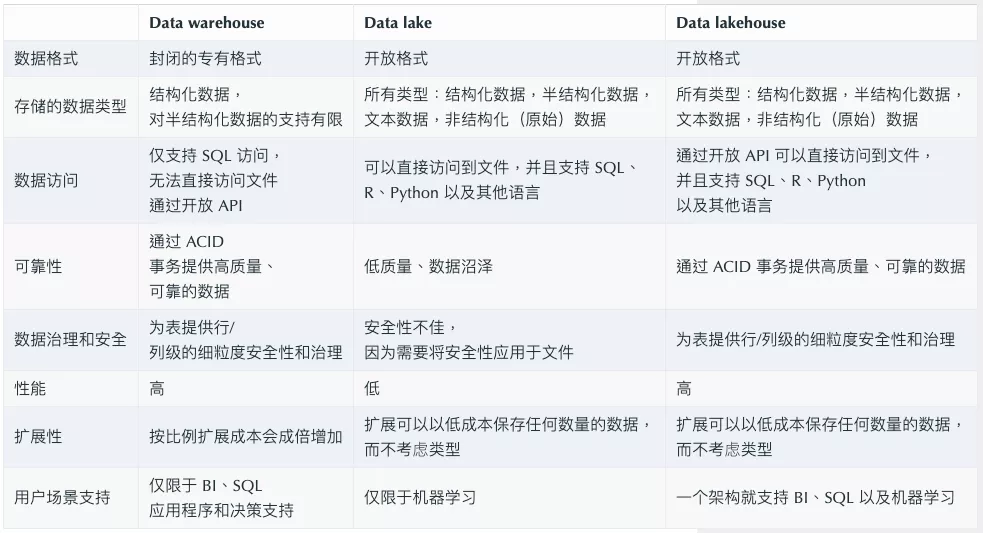
数据仓库(Data Warehouse) & 数据湖(Data Lake) & 湖仓一体(Lake house)
AWS对数据湖下的最简单易理解的定义:数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。


| 对比维度 | 数据湖 | 数据仓库 |
|---|---|---|
| 方法论 | 事后建模 Schema-on-Read | 事前建模 Schema-on-Write |
| 存储类型 | 结构化、半结构化、非结构化 | 结构化、半结构化 |
| 计算引擎 | 向所有引擎开放(各引擎有限优化) | 向特定引擎开放(易获得高度优化) |
| 运维 | 难运维管理(易启动) | 易运维管理(甚至免运维管理)(难启动) |
| 数据质量 | 质量低(难管理使用) | 质量高(易管理使用) |
数据仓库
数据仓库greenplum、clickhouse、doris
kudu加impala
通常是业务发展到一定规模后,业务分析师、CIO、决策者们,希望从大量的应用系统、业务数据中,进行关联分析,最终整点“干货”出来。
比如为啥利润会下滑?为啥库存周转变慢了?向数据要答案,整点报告、图表出来给老板汇报,辅助经营决策。
可是,数据库“脑容量不足”,擅长事务性工作,不擅长分析型的工作,于是就产生了数据仓库。
虽然现在HTAP的概念很盛行,也就是混合事务/分析处理,用一套数据库架构来同时支持事务(OLTP)和分析(OLAP)两种需求,但真正大规模的分析和洞察,还是离不开数据仓库。
数据仓库相当于一个集成化数据管理的平台,从多个数据源抽取有价值的数据,在仓库内转换和流动,并提供给BI等分析工具来输出干货。

因为分析型业务需要大量的“读”操作,所以数据仓库通过“Denormalized”化的方式优化表结构,减少表间联接,牺牲空间来换取读性能。(一张表里的冗余数据增加了,但查询起来却更快了),并使用列式存储优化,来进一步提高查询速度、降低开销。
再结合面向分析场景的Schema设计,数据仓库就可以高效率、全方位、多维度的扛起“联机分析”重任了。

围绕数据仓库的分析基础设施包含以下内容:
• 元数据(Metadata)– 一个关于数据位于何处的指南;
• 数据模型(A data model)– 数据仓库中数据的抽象;
• 数据血缘(Data lineage)– 数据仓库中数据的起源和转换;
• 摘要(Summarization)– 用于创建数据的算法工作的描述;
• KPIs – 关键绩效指标在哪里;
• ETL – 允许将应用程序数据转换为公司数据。
一般情况下,数据仓库里面的数据是结构化的数据。但是现在公司中有许多其他的数据类型,包括结构化(Structured data)、文本数据(Textual data)以及非结构化(unstructured data)的数据。
结构化数据通常是组织为执行日常业务活动而生成的基于事务(transaction-based)的数据。文本数据是由公司内部发生的信件、电子邮件和对话生成的数据。非结构化数据是其他来源的数据,如物联网数据、图像、视频和基于模拟的数据。
数据湖是企业中所有不同类型数据的集合。
Databend: 云原生数仓
https://github.com/datafuselabs/databend
数据湖(Data Lake)
数据库负责干事务处理相关的事,数据仓库负责干业务分析相关的事,还有新兴的HTAP数据库既干事务又干分析,都已经这么内卷了,还要数据湖来干个毛线?
2010年,James Dixon提出数据湖(Data Lake)的概念。
2011年Dan Woods在福布斯发表“大数据需要更大的新架构”(Big Data Requires a Big New Architecture),数据湖开始广为传播。

数据湖是与数据仓库相对的概念。数据仓库有两个局限:一是只可以回答预先设定的问题,二是数据已经被筛选包装好,无法看见其最初状态。
数据湖的核心原则是集中存储原始的、未经改变的全量数据,在提取数据时才进行转换。数据湖存储各种类型数据,重点是非结构化和半结构化数据,通过统一视图提供开放访问。数据湖具有强大的元数据管理能力,保证所存储数据资源的语义一致性,这是进行大数据分析的基本前提。
数据湖的本质,是由“➊数据存储架构+➋数据处理工具”组成的解决方案,而不是某个单一独立产品。
- ➊数据存储架构,要有足够的扩展性和可靠性,要满足企业能把所有原始数据都“囤”起来,存得下、存得久。
- ➋数据处理工具,则分为两大类↓
第一类工具,解决的问题是如何把数据“搬到”湖里,包括定义数据源、制定数据访问策略和安全策略,并移动数据、编制数据目录等等。
如果没有这些数据管理/治理工具,元数据缺失,湖里的数据质量就没法保障,“泥石俱下”,各种数据倾泻堆积到湖里,最终好好的数据湖,慢慢就变成了数据沼泽。
因此,在一个数据湖方案里,数据移动和管理的工具非常重要。
比如,Amazon Web Services提供“Lake Formation”这个工具,帮助客户自动化地把各种数据源中的数据移动到湖里,同时还可以调用Amazon Glue来对数据进行ETL,编制数据目录,进一步提高湖里数据的质量。
第二类工具,就是要从湖里的海量数据中“淘金”。
数据并不是存进数据湖里就万事大吉,要对数据进行分析、挖掘、利用,比如要对湖里的数据进行查询,同时要把数据提供给机器学习、数据科学类的业务,便于“点石成金”。
我们继续拿Amazon Web Services来举例子,基于Amazon Athena这个服务,就可以使用标准的SQL来对S3(数据湖)中的数据进行交互式查询。


湖仓一体(Lake house / data lakehouse)
为什么要把“湖”和“仓”糅到一起?
曾经,数据仓库擅长的BI、数据洞察离业务更近、价值更大,而数据湖里的数据,更多的是为了远景画饼。
随着大数据和AI的上纲上线,原先的“画的饼”也变得炙手可热起来,为业务赋能,价值被重新定义。
而因为数仓和数据库的出发点不同、架构不同,企业在实际使用过程中,“性价比”差异很大。

数据湖起步成本很低,但随着数据体量增大,TCO成本会加速飙升,数仓则恰恰相反,前期建设开支很大。
总之,一个后期成本高,一个前期成本高,对于既想修湖、又想建仓的用户来说,仿佛玩了一个金钱游戏。
于是,人们就想,既然都是拿数据为业务服务,数据湖和数仓作为两大“数据集散地”,能不能彼此整合一下,让数据流动起来,少点重复建设呢?
比如,让“数仓”在进行数据分析的时候,可以直接访问数据湖里的数据(Amazon Redshift Spectrum是这么干的)。再比如,让数据湖在架构设计上,就“原生”支持数仓能力(DeltaLake是这么干)。
数据库、数据湖、数据仓库、湖仓一体、智能湖仓,分别都是什么鬼
OPPO数据湖统一存储技术实践
| Data warehouse | Data lake | Data lakehouse | |
|---|---|---|---|
| Data format | Closed, proprietary format | Open format | Open format |
| Types of data | Structured data, with limited support for semi-structured data | All types: Structured data, semi-structured data, textual data, unstructured (raw) data | All types: Structured data, semi-structured data, textual data, unstructured (raw) data |
| Data access | SQL-only, no direct access to file | Open APIs for direct access to files with SQL, R, Python and other languages | Open APIs for direct access to files with SQL, R, Python and other languages |
| Reliability | High quality, reliable data with ACID transactions | Low quality, data swamp | High quality, reliable data with ACID transactions |
| Governance and security | Fine-grained security and governance for row/columnar level for tables | Poor governance as security needs to be applied to files | Fine-grained security and governance for row/columnar level for tables |
| Performance | High | Low | High |
| Scalability | Scaling becomes exponentially more expensive | Scales to hold any amount of data at low cost, regardless of type | Scales to hold any amount of data at low cost, regardless of type |
| Use case support | Limited to BI, SQL applications and decision support | Limited to machine learning | One data architecture for BI, SQL and machine learning |
简述数据仓库、OLAP、数据挖掘之间的关系
-
数据仓库是基础:无论是数据挖掘还是OLAP分析,他们成功的关键之一是能够访问正确的、完整的和集成的数据。这也是对数据仓库的要求。数据仓库不仅是集成数据的一种方式和一个焦点,而且所有的数据仓库的解决方案都源自和依赖于数据源部件的质量和效果(这种部件在数据仓库中称为抽取、变换和装载)。数据仓库的特点(集成的、随时间变化、稳定的、面向主题的)为OLAP分析、数据挖掘的成功提供了坚实的数据基础。
-
OLAP和数据挖掘的区别:OLAP与数据挖掘都是数据库或数据仓库的分析工具,是相辅相成,都是决策分析不可缺少的工具。但他们又有不同,OLAP是验证型的分析工具,而数据挖掘是预测型的工具。 OLAP建立在多维视图的基础之上,强调执行效率和对用户命令的及时响应,而且其直接数据源一般是数据仓库;数据挖掘建立在各种数据源的基础上,能够自动分析发现隐藏在数据深层次的对人们有用的模式(Patterns),一般并不过多考虑执行效率和响应速度。
OLAP是一种自上而下、不断深入的分析工具;用户提出问题或假设,通过OLAP从上而下地提取出关于该问题地详细信息,并且以可视化的方式呈现给用户。与数据挖掘相比,OLAP更多地依靠用户提供的问题和假设,受用户的思维习惯所影响。
数据挖掘常能挖掘出超越归纳范围的关系,但OLAP仅能利用人工查询及可视化的报表来确认某些关系,是以数据挖掘此种自动找出甚至不会被怀疑过的数据关系的特性,事实上己超越了我们经验、教育、想象力的限制,OLAP可以和数据挖掘互补,但这项特性是数据挖掘无法被OLAP取代的。
- 数据挖掘与数据仓库的关系:尽管数据挖掘技术扎根于计算科学和数学,但两者的结合能给数据挖掘带来各种便利和功能。
首先,数据挖掘有一个昂贵的数据清理、数据变换和数据集成的过程,作为数据的预处理。而已经完成数据清理、数据变换和数据集成的数据仓库,完全能为数据挖掘提供它所需要的挖掘数据。
其次,数据仓库能为数据挖掘提供各种数据库连接、WEB访问和服务工具以及报表与OLAP分析工具等全面的数据处理和数据分析等基础设施。
最后,在数据挖掘工程中,如果将数据挖掘与数据仓库进行有效的联结,将增加数据挖掘的联机挖掘功能。
商业智能(BI)
商业智能(Business Intelligence,简称BI)的关键是从许多来自不同的企业运作系统的数据中提取出有用的数据并进行清理,以保证数据的正确性,然后经过抽取(Extraction)、转换(Transformation)和装载(Load),即ETL过程,合并到一个企业级的数据仓库里,从而得到企业数据的一个全局视图,在此基础上利用合适的查询和分析工具、数据挖掘工具、OLAP工具等对其进行分析和处理(这时信息变为辅助决策的知识),最后将知识呈现给管理者,为管理者的决策过程提供支持。
简单来说,BI通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的工具。为了将数据转化为知识,需要利用数据仓库、联机分析处理(OLAP)工具和数据挖掘等技术。
维度和度量
维度和度量是数据分析中的两个基本概念。
维度是人们观察数据的特定角度,是考虑问题的一类属性。他通常是数据记录的一个特征,如时间、地点等。同时,维度具有层级概念,可能存在细节程度不同的描述方面,如日期、月份、季度、年等。
在数仓中,可以在数学上求和的事实属性称为度量。例如,可以对度量进行总计、平均、以百分比形式使用等。度量是维度模型的核心。通常,在单个查询中检索数千个或数百万个事实行,其中对结果集执行数学方程。
在一个SQL查询中,Group by的属性通常就是维度,而所计算的值则是度量。
OLAP
联机事务处理 OLTP(Online Transaction Processing)
联机分析处理 OLAP(OnLine Analytical Processing)
混合事务分析处理 HTAP (Hybrid Transactional/Analytical Processing)
开源 OLAP 引擎测评报告(SparkSql、Presto、Impala、HAWQ、ClickHouse、GreenPlum)
你需要的不是实时数仓 | 你需要的是一款合适且强大的 OLAP 数据库(上)
你需要的不是实时数仓 | 你需要的是一款强大的 OLAP 数据库(下)
数据处理大致可以分成两大类:
- 联机事务处理 OLTP(On-line Transaction Processing)
OLTP 是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。 - 联机分析处理 OLAP(On-Line Analytical Processing)
OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLAP(On-line Analytical Processing,联机分析处理)根据存储数据的方式不同可以分为ROLAP、MOLAP、HOLAP。ROLAP表示基于关系数据库存储的OLAP实现(Relational OLAP),以关系数据库为核心,以关系型结构进行多维数据的表示和存储;MOLAP表示基于多维数据存储的OLAP实现(Multidimensional OLAP);HOLAP表示基于混合数据存储的OLAP实现(Hybrid OLAP),如低层用关系型数据库存储,高层是多维数组存储。
MOLAP,基于多维数组的存储模型,也是OLAP最初的形态,特点是对数据进行预计算,以空间换效率,明细和聚合数据都保存在cube中。但生成cube需要大量时间和空间。
MOLAP: 通过基于数据立方体的多位存储引擎,支持数据的多位视图。即通过将多维视图直接映射到数据立方体上,使用数据立方体能够将预计算的汇总数据快速索引。比较典型的MOLAP框架有kylin(apache), Lylin(ebay)、pinot(linkedin)和druid
也就是说MOLAP是空间换时间,即把所有的分析情况都物化为物理表或者视图,查询的时候直接从相应的物化表中获取数据, 而ROLAP则通过按维度分库,分表等方式,实现单一维度下的快速查询,通过分布式框架,并行完成分析任务,来实现数据的分析功能。MOLAP 实现较简单,但当分析的维度很多时,数据量呈指数增长,而ROLAP在技术实现上要求更高,但扩展性也较好。
ROLAP,完全基于关系模型进行存储数据,不需要预计算,按需即时查询。明细和汇总数据都保存在关系型数据库事实表中。
ROLAP将多维数据库中的表分为两类:事实表和维度表。事实表用于存储维度关键字和数值类型的事实数据,一般是围绕业务过程进行设计,例如:销售事实表,一般来存储用户在什么时间、地点购买了产品,销量和销售额等信息。维度表用于存储维度的详细数据,例如销售事实表中存储了产品维度的ID,产品维度表中存储产品的名称、品牌信息,两者通过产品ID进行关联。
ROLAP根据事实表、维度表间的关系,又可分为星型模型(Star Schema)、雪花模型(Snowflake Schema)。
ROLAP: 使用关系型数据库或者扩展的关系型数据库来管理数据仓库数据,而OLAP中间件支持其余的功能。ROLAP包含了每个后端关系型数据库的优化,聚合,维度操作逻辑的实现,附件的工具以及服务等。所以ROLAP比MOLAP有更好的可伸缩性。 比较典型的ROLAP有mondrian, Presto(facebook)。目前阿里的DRDS也可以看作是ROLAP的框架
HOLAP,混合模型,细节数据以ROLAP存放,聚合数据以MOLAP存放。这种方式相对灵活,且更加高效。可按企业业务场景和数据粒度进行取舍,没有最好,只有最适合。
HOLAP: 混合OLAP结合ROLAP和MOLAP,得益于ROLAP较大的可伸缩性和MOLAP的快速查询。
更多的关于OLAP的知识,推介大家看机械工业出版社出版的《数据挖掘-概念与技术》
MOLAP可选Kylin、Druid等;ROLAP可选ClickHouse、Doris等。
OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
OLAP 开源引擎
目前市面上主流的开源 OLAP 引擎包含不限于:Hive、Hawq、Presto、Kylin、Impala、Sparksql、Druid、Clickhouse、Greeplum、Doris、Drill、AnalyticDB、HBase/Phoenix、Kudu等,可以说目前没有一个引擎能在数据量,灵活程度和性能上做到完美,用户需要根据自己的需求进行选型。
上面给出了常用的一些 OLAP 引擎,它们各自有各自的特点,我们将其分组:
- Hive,Hawq,Impala - 基于 SQL on Hadoop
- Presto 和 Spark SQL 类似 - 基于内存解析 SQL 生成执行计划
- Kylin - 用空间换时间,预计算
- Druid - 一个支持数据的实时摄入
- ClickHouse - OLAP 领域的 Hbase,单表查询性能优势巨大
- Greenpulm - OLAP 领域的 Postgresql
如果你的场景是基于 HDFS 的离线计算任务,那么 Hive,Hawq 和 Imapla 就是你的调研目标;
如果你的场景解决分布式查询问题,有一定的实时性要求,那么 Presto 和 SparkSQL 可能更符合你的期望;
如果你的汇总维度比较固定,实时性要求较高,可以通过用户配置的维度+指标进行预计算,那么不妨尝试 Kylin 和 Druid;
ClickHouse 则在单表查询性能上独领风骚,远超过其他的 OLAP 数据库;
Greenpulm 作为关系型数据库产品,性能可以随着集群的扩展线性增长,更加适合进行数据分析。
SQLServer 内置的 OLAP 工具 Analysis Manager 可以允许用户访问异构数据库,提供支持 OLAP 分析的高速缓存和计算引擎
SQL Server Analysis Services OLAP 引擎服务器组件
Apache Pinot
Pinot 是一个实时分布式的 OLAP 数据存储和分析系统。
使用它实现低延迟可伸缩的实时分析。
Pinot 从脱机数据源(包括 Hadoop 和各类文件)和在线数据源(如 Kafka)中获取数据进行分析。
Pinot 被设计成可进行水平扩展。
Pinot 特别适合这样的数据分析场景:查询具有大量维度和指标的时间序列数据、分析模型固定、数据只追加以及低延迟,以及分析结果可查询。
Apache Kylin
Apache Kylin™ 是一个开源、分布式的大数据分析数据仓库;它被设计为在大数据时代提供 OLAP(在线分析处理)能力。通过对 Hadoop 和 Spark 上的多维立方体和预计算技术的革新,Kylin 能够在数据量不断增长的情况下实现近乎恒定的查询速度。Kylin 将查询延迟从几分钟缩短到次秒,将在线分析带回到大数据。
Apache Doris(原 Palo)
https://github.com/apache/incubator-doris
Apache Kylin VS Apache Doris 全方位对比
Doris 是一个 MPP 的 OLAP 系统,主要整合了 Google Mesa(数据模型),Apache Impala(MPP Query Engine)和 Apache ORCFile (存储格式,编码和压缩) 的技术。
Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。使得数据分析工作更加简单高效!
其它
数据库监控
DBA Dash
SQL Server监控工具
https://github.com/trimble-oss/dba-dash
sqlwatch
SQL Server Performance Monitor
MySQL
MySQLTuner-perl: https://github.com/major/MySQLTuner-perl
Anemometer慢SQL查询监控:https://github.com/box/Anemometer
MySQL监控工具: https://github.com/charles-001/dolphie
Blip MySQL Monitor: https://github.com/cashapp/blip
PostgreSQL
https://github.com/thumbtack/pgdoctor 没有更新了
https://github.com/lob/pg_insights 只读了
https://github.com/mfvanek/pg-index-health-sql
https://github.com/cybertec-postgresql/pgwatch2
https://github.com/ankane/pghero
docker run -itd -e DATABASE_URL=postgres://user:password@hostname:5432/pgherodbname -p 8080:8080 ankane/pghero
Percona Monitoring and Management
Percona Monitoring and Management, PMM
PMM Client
每个PMM客户端收集有关常规系统和数据库性能的各种数据,并将该数据发送到相应的PMM服务器。
PMM客户端软件包包括以下内容:
- pmm-admin是用于管理PMM客户端的命令行工具,例如,添加和删除要监视的数据库实例。
- pmm-agent是客户端组件,是最小的命令行界面,它是带来客户端功能的中央入口点:它进行客户端的身份验证,将客户端配置存储在PMM服务器上,管理导出器和其他代理商。
- node_exporter是一个Prometheus导出器,用于收集常规系统指标。
- mysqld_exporter是Prometheus导出器,用于收集MySQL服务器指标。
- mongodb_exporter是一个Prometheus导出器,用于收集MongoDB服务器指标。
- postgres_exporter是Prometheus导出器,用于收集PostgreSQL性能指标。
- proxysql_exporter是一个Prometheus导出器,用于收集ProxySQL性能指标。
PMM Server

PMM服务器包括以下工具:
使用查询分析(QAN),您可以分析一段时间内的MySQL查询性能。除客户端QAN代理外,它还包括以下内容:
- QAN API是用于存储和访问由PMM客户端上运行的QAN代理收集的查询数据的后端。
- QAN Web App是用于可视化收集的查询分析数据的Web应用程序。
指标监视器提供了对MySQL或MongoDB服务器实例至关重要的指标的历史视图。它包括以下内容:
- Prometheus是第三方时间序列数据库,它连接到在PMM客户端上运行的出口商,并汇总由出口商收集的指标。
- ClickHouse是第三方的面向列的数据库,可促进Query Analytics功能。
- Grafana是第三方仪表板和图形构建器,用于在直观的Web界面中可视化Prometheus聚合的数据。
我们可以从PMM Server Web界面(登录页面)访问所有工具。
- 部署PMM Server
# 拉取镜像
docker pull percona/pmm-server:2.9.1
# 建立持久化数据卷
docker create --volume /srv --name pmm-data percona/pmm-server:2.9.1 /bin/true
# 启动server
docker run --detach --restart always --publish 80:80 --publish 443:443 --volumes-from pmm-data --name pmm-server percona/pmm-server:2.9.1
- 部署PMM Client
(2.1)添加基础监控
# 1.安装client
# pmm-client 和 pmm-server版本一定要匹配,都为2 或 都为1。
# percona/pmm-server:latest 的版本为1.X
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install pmm2-client
# 2.配置并连接server
# pmm-admin config --server-insecure-tls --server-url=https://admin:admin@192.168.3.101:443
Checking local pmm-agent status...
pmm-agent is running.
Registering pmm-agent on PMM Server...
Registered.
Configuration file /usr/local/percona/pmm2/config/pmm-agent.yaml updated.
Reloading pmm-agent configuration...
Configuration reloaded.
Checking local pmm-agent status...
pmm-agent is running.
# 3. 查看监控列表
# pmm-admin list
Service type Service name Address and port Service ID
Agent type Status Agent ID Service ID
pmm_agent Connected /agent_id/83d7c918-099f-4f62-aab8-c2024b0f1227
node_exporter Running /agent_id/83e09526-d877-4019-a574-a8da90e6dcbc
pmm client 与server 建立连接后,默认使用node_exporter收集服务器CPU、Memory、Disk等基本状态信息。
(2)添加mysql监控
# 1.添加监控账户
grant all on *.* to grafana@'%' identified by 'grafana';
# 2.添加mysql监控
pmm-admin add mysql --username=grafana --password=grafana --query-source=perfschema --service-name=perfschema-mysql --host=127.0.0.1 --port=3306 --disable-tablestats-limit=50000
# 3.查看监控
# pmm-admin list
Service type Service name Address and port Service ID
MySQL perfschema-mysql 127.0.0.1:3306 /service_id/ea7032c2-1000-47b3-84e7-f2d41c58a065
Agent type Status Agent ID Service ID
pmm_agent Connected /agent_id/83d7c918-099f-4f62-aab8-c2024b0f1227
node_exporter Running /agent_id/83e09526-d877-4019-a574-a8da90e6dcbc
mysqld_exporter Running /agent_id/cb95c179-58e7-46d1-a43e-76874df07889 /service_id/ea7032c2-1000-47b3-84e7-f2d41c58a065
mysql_perfschema_agent Running /agent_id/f920ffe3-2f79-4be9-ad65-93ef5fbe19a3 /service_id/ea7032c2-1000-47b3-84e7-f2d41c58a065
# 4. 删除监控
pmm-admin remove mysql perfschema-mysql
数据库性能测试工具
SysBench
https://github.com/akopytov/sysbench c 3.5k
支持系统:
- Linux
- macOS
- Windows
目前 sysbench 主要支持 MySQL,pgsql,oracle
SysBench 是一个模块化的、跨平台、多线程基准测试工具,主要用于评估测试各种不同系统参数下的数据库负载情况。它主要包括以下几种方式的测试:
1、cpu 性能
2、磁盘 io 性能
3、调度程序性能
4、内存分配及传输速度
5、POSIX 线程性能
6、数据库性能(OLTP 基准测试)
dbbench
https://github.com/memsql/dbbench
- mysql
- mssql
- pgsql
数据库同步
Canal、Debezium、DataX、Databus、Flinkx、Bifrost。

GoldenGate
DataPipeline
Pglogical
canal
Maxwell
Debezium
https://github.com/debezium/debezium 3.8k
可以同步数据到 kafka
Debezium 是一个开源项目,为捕获数据更改(Capture Data Change,CDC)提供了一个低延迟的流式处理平台,通过安装配置 Debezium 监控数据库,可以实时消费行级别(row-level)的更改。身为一个分布式系统,Debezium 也拥有良好的容错性。
Debezium 是一种借助 Kafka 将数据变更发布成事件流的 CDC 实现。
Debezium 是一款开源的、基于 Kafka 的 CDC 工具,它会读取数据库事务日志,并将其发布成事件流。
CDC 除了可以用来更新缓存、服务和搜索引擎,Morling 还介绍了其他几种用例,包括:
- 数据复制,通常用来将数据复制到其他类型的数据库或数据仓库中。
- 审计。因为保留了数据历史,在使用元数据填充数据后,可以实现数据变更审计。
Debezium 的源端(即支持监控哪些数据库) :
- MySQL
- MongoDB
- PostgreSQL
- Oracle
- SQL Server
- Oracle (Incubating)
- Db2 (Incubating)
- Cassandra (Incubating)
数据库连接器
Debezium 的目标端(即可以数据导入端) : Kafka
Debezium 获取 MySQL Binlog
使用嵌入式 Debezium 和 SpringBoot 捕获更改数据事件(CDC) - Sohan Ganapathy
如果您已经安装了 Zookeeper、Kafka 和 Kafka Connect,那么使用 Debezium 的连接器是很容易的。只需下载一个或多个连接器插件存档(见下文),将它们的文件解压到 Kafka Connect 环境中,并将解压后的插件的父目录添加到 Kafka Connect 的插件路径中。如果不是这样,在你的工作配置中指定插件路径(例如,connect- distribu. properties)使用插件。路径配置属性。例如,假设您已经下载了 Debezium MySQL 连接器存档,并将其内容解压缩到/kafka/connect/ Debezium -connector- MySQL。然后在 worker 配置中指定以下内容:plugin.path=/kafka/connect
数据湖方案
- ACID 和隔离级别支持
| Solution | ACID Support | Isolation Level | Concurrent Multi-Writers | Time Travel |
|---|---|---|---|---|
| Iceberg | Yes | Write Serialization | Yes | Yes |
| Hudi | Yes | Snapshot Isolation | Yes | Yes |
| Open Delta | Yes | SerializationWrite SerializationSnapshot Isolation | Yes | Yes |
| Hive ACID | Yes | Snapshot Isolation | Yes | No |
三种隔离分别代表的含义:
-
Serialization 是说所有的 reader 和 writer 都必须串行执行;
-
Write Serialization: 是说多个 writer 必须严格串行,reader 和 writer 之间则可以同时跑;
-
Snapshot Isolation: 是说如果多个 writer 写的数据无交集,则可以并发执行;否则只能串行。Reader 和 writer 可以同时跑。
-
Schema 变更支持和设计
| Solution | Schema Evolution | Self-defined schema object |
|---|---|---|
| Iceberg | all | Yes |
| Hudi | back-compatible | No(spark-schema) |
| Open Delta | all | No(spark-schema) |
| Hive ACID | all | No(Hive-schema) |
iceberg 是做的比较好的,抽象了自己的 schema,不绑定任何计算引擎层面的 schema。
-
流批接口支持
目前 Iceberg 和 Hive 暂时不支持流式消费,不过 Iceberg 社区正在 issue 179 上开发支持。 -
接口抽象程度和插件化
| Solution | Engine Pluggable(Write Path) | Engine Pluggable(Read Path) | Storage Pluggable (Less Storage API Binding) | Open File Format |
|---|---|---|---|---|
| Iceberg | Yes | Yes | Yes | Yes |
| Hudi | No(Bind with spark) | Yes | Yes | Yes(data) + No(Log) |
| Open Delta | No(Bind with spark) | Yes | Yes | Yes |
| Hive ACID | Yes | Yes | No | No(Only ORC) |
- 查询性能优化
| Solution | Filter PushDown | Low meta cast | Indexing within partitions Boost the perf of selective queries | CopyOnWrite | MergeOnRead | Auto-Compaction |
|---|---|---|---|---|---|---|
| Iceberg | Yes | Yes | Road-map | Yes | On-going | No |
| Hudi | No | Yes | - | Yes | Yes | Yes |
| Open Delta | No | Yes | - | Yes | No | No |
| Close Delta | Yes | Yes | Yes | Yes | Yes | Yes |
| Hive ACID | Yes | No | - | No | Yes | Yes |
- 其他功能
| Solution | One line demo | Python Support | File Encryption | Cli Command |
|---|---|---|---|---|
| Iceberg | Not Good | Yes | Yes | No |
| Hudi | Medium | No | No | Yes |
| Open Delta | Good | Yes | No | Yes |
| Close Delta | Good | Yes | No | Yes |
| Hive ACID | Medium | No | No | Yes |
- 社区现状(截止到 2020-11-05)
| Solution | Open Source Time | Github Star | Github Fork | Github Issues | Contributors |
|---|---|---|---|---|---|
| Iceberg | 2018/11/06 | 805 | 312 | 237 | 106 |
| Hudi | 2019/01/17 | 1.5k | 638 | 52 | 122 |
| Open Delta | 2019/04/12 | 2.9k | 635 | 131 | 76 |
总结成如下图:

Delta
Databricks 的 Delta
开源的 delta 是 databricks 闭源 delta 的一个简化版本
Apache Iceberg
Netflix 的 Apache Iceberg
也有用Iceberg做湖仓一体化
Apache Hudi
Uber 的 Apache Hudi