 img
img- shell
- yml
 awesome.md
awesome.md- build-1.18.md
- build.md
- Calico.md
- cdk8s.md
- cmd.md
- CNI.md
- configmap.md
- CRD.md
- CSI.md
- doc1.md
- doc2.md
- docker-for-desktop.md
- elasticsearch.md
- FAQ.md
- healthcheck.md
- helm.md
- hpa.md
- images.md
- ingress-nginx.md
- install-ansible.md
- install.md
- install_2.md
- istio-1.md
- istio-canary.md
- Istio-Envoy组件分析.md
- istio-feature.md
- istio-install-1.5.md
- istio-install.md
- istio-new-version.md
- istio-wasm.md
- istio.md
- job.md
- k3s.md
- k8s-affinity.md
- k8s-allocatable.md
- k8s-arkade.md
- k8s-canary.md
- K8s-deployment-yaml.md
- k8s-disk.md
- k8s-krustlet.md
- k8s-kubelet.md
- k8s-logs.md
- k8s-new-version.md
- k8s-node.md
- k8s-pod-eviction.md
- k8s-pod-lifetime.md
- k8s-runtime.md
- k8s-scheduling-framework-plugins.md
- k8s-service.md
- k8s-strategy-RollingUpdate.md
- k8s-troubleshooting-pod.md
- k8s-troubleshooting.md
- k8s-webhook.md
- k8s_endpoint.md
- kafka.md
- kong.md
- kubectl-cheat-sheet.md
- kubectl-debug.md
- kubectl-plugin.md
- kubernetes-handling-client-requests.md
- Kubernetes-Networking.md
- kubernetes-storage.md
- linkerd2.md
- lxcfs.md
- minikube.md
- OAM.md
- OpenShift.md
- Operator.md
- postgres.md
- Prometheus-2.md
- prometheus.md
- Prometheus_HPA.md
- Prometheus_HPA_2.md
- PV.md
- RBAC.md
- README.md
- Service-Mesh.md
- Sidecar.md
- SMI.md
- solo-gloo-gateway.md
- solo-wasm-filter.md
- source-code.md
- traefik-ingress.md
- webhook.md
- zipkin.md
Table of Contents
k3s
轻量级Kubernetes
k3s是经CNCF一致性认证的Kubernetes发行版,专为物联网及边缘计算设计。
k3d管理k3s
k3d: 在 Docker 中运行 k3s
命令方式
k3d cluster create mycluster --api-port 127.0.0.1:6445 --servers 3 --agents 2 --volume '/home/me/mycode:/code@agent[*]' --port '8080:80@loadbalancer'
这条命令创建带有 6 个容器的 K3s 集群:
- 1 个负载均衡器
- 3 个服务器 (控制位面节点)
- 2 个 agents (以前的工作节点)
使用 --api-port 127.0.0.1:6445 参数,你可以告诉 k3d 将 Kubernetes API 端口映射到 127.0.0.1/localhost 的端口 6445。这意味着你可以在你的 Kubeconfig 中使用这个连接串 server:https://127.0.0.1:6445 来连接到集群。
本端口也会将你的负载均衡器映射到你的宿主机。从这开始,请求将被代理到你的服务器节点。有效模拟生产环境的设置,这样你的服务器节点也可以下线,你会期望它故障转移到其它节点上。
而 --volume /home/me/mycode:code@agent[*] 将你的本地目录 /home/me/mycode 绑定到你所有的 agent 节点的路径 /code 。将 * 替换为索引 (这里是 0 或者 1) 来仅仅绑定到其中之一。
告诉 k3d 哪些节点应该挂载卷的规范被称为 节点过滤,它也被用于其它标志中,例如用于端口映射的 --port 标志。
也就是说,--port 8080:80@loadbalancer 将你的本地端口 8080 映射到负载均衡器 (serverlb) 的 80 端口,它可以用来转发 HTTP 入口流量到你的集群中。例如,你现在可以部署一个 web 应用到集群中 (Deployment),它可以通过类似于 myapp.k3d.localhost 向外部暴露出 (Service)。
然后 (提供将域名解析到你的本地宿主 IP 的所有设置),你可以使用浏览器访问 http://myapp.k3d.localhost:8080 来访问你的应用。访问流量通过你的宿主穿过 Docker 网桥界面到达负载均衡器。从这里 it 代理集群,将流量转发到你的应用所在 Pod 中的 Service。
注意:你需要做一些设置来将你的 myapp.k3d.localhost 解析到你的本地宿主 IP (127.0.0.1)。最常用的方式是在你的 /etc/hosts 文件 (Windows 中是 C:\Windows\System32\drivers\etc\host) 中使用如下设置:
127.0.0.1 myapp.k3d.localhost
不过,这种方式不支持统配符 (*.localhost),所以随后可能会变得琐碎,所以,你可能希望看一下这个工具 (https://en.wikipedia.org/wiki/Dnsmasq" dnsmasq (MacOS/UNIX) or https://stackoverflow.com/a/9695861/6450189" Acrylic (Windows)) 来简化一下。
提示: 你可以在有些系统上安装包 libnss-myhostname (至少 Linux 操作系统,包括 SUSE 和 OpenSUSE) 来自动解析 *.localhost 域名到 127.0.01,这样你就不需要反复处理 /etc/hosts 文件,如果你倾向于通过 Ingress 测试,你需要设置一个域名。
有趣的一件事需要提示一下:如果你创建了多于 1 个的服务器节点,K3s 将提供 --cluster-init 参数,这意味着它切换内部的数据存储 (默认是 SQLite) 用于 etcd。
配置即代码方式
从 k3d v4.0.0 ( 2021 年 1月) 开始,我们支持使用配置文件来通过代码配置所有你前面使用命令参数方式的配置。
在本文编写的时候,用来验证配置文件有效性的 JSON Schema 可以在这里找到
这里是一个配置文件示例:
k3d configuration file, saved as e.g. /home/me/myk3dcluster.yaml
apiVersion: k3d.io/v1alpha2 # this will change in the future as we make everything more stable
kind: Simple # internally, we also have a Cluster config, which is not yet available externally
name: mycluster # name that you want to give to your cluster (will still be prefixed with `k3d-`)
servers: 1 # same as `--servers 1`
agents: 2 # same as `--agents 2`
kubeAPI: # same as `--api-port 127.0.0.1:6445`
hostIP: "127.0.0.1"
hostPort: "6445"
ports:
- port: 8080:80 # same as `--port 8080:80@loadbalancer
nodeFilters:
- loadbalancer
options:
k3d: # k3d runtime settings
wait: true # wait for cluster to be usable before returining; same as `--wait` (default: true)
timeout: "60s" # wait timeout before aborting; same as `--timeout 60s`
k3s: # options passed on to K3s itself
extraServerArgs: # additional arguments passed to the `k3s server` command
- --tls-san=my.host.domain
extraAgentArgs: [] # addditional arguments passed to the `k3s agent` command
kubeconfig:
updateDefaultKubeconfig: true # add new cluster to your default Kubeconfig; same as `--kubeconfig-update-default` (default: true)
switchCurrentContext: true # also set current-context to the new cluster's context; same as `--kubeconfig-switch-context` (default: true)
假设我们将它保存为文件 /home/me/myk3dcluster.yaml,你可以如下使用它来配置一个集群。
k3d cluster create --config /home/me/myk3dcluster.yaml
注意,你仍然可以使用额外的参数,它们优先于配置文件中的配置使用。
参考
https://www.cnblogs.com/haogj/p/16397876.html
边缘计算
IOT
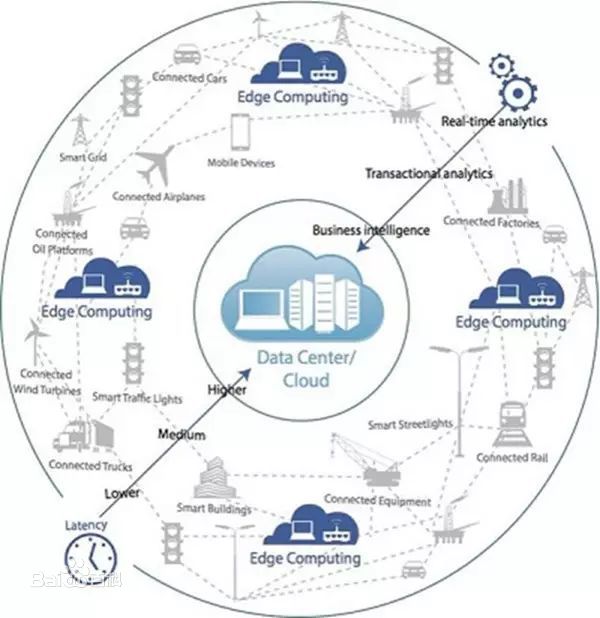
论是云、雾还是边缘计算,本身只是实现物联网、智能制造等所需要计算技术的一种方法或者模式。严格讲,雾计算和边缘计算本身并没有本质的区别,都是在接近于现场应用端提供的计算。就其本质而言,都是相对于云计算而言的。
https://www.toutiao.com/i6754155394181890573/
https://www.toutiao.com/i6740789249601176072/
边缘计算是一项新兴的技术,它能够在位置偏远、资源受限的情况下对数据进行处理。因此,边缘计算在这个时代里扮演着极为重要的角色。著名调查机构Gartner预计,到2025年将有75%的数据在传统的数据中心或云外部处理。我们可以分析通过从边缘网络获取的数据,进而快速做出决策。
物联网(IoT)设备是一种典型的边缘计算设备,因为数据分析发生在这些连接的设备中,这些设备远离数据中心,但是可以直接在边缘上处理信息。边缘计算这一技术可以在微小型数据中心上(如办公室或分支机构)处理数据而不是将数据发送到大型的数据中心,这迎合了本地计算的需求。而微数据设备更是切准了边缘计算的需求。可以说边缘计算是一种减少了部分本地技术,来适应特定商业需求的技术。如果我们想要发挥计算的真正优势,保证IT基础架构能够运行任何数据中心(本地部署或外部部署)是关键。
边缘计算中的常用概念
以下我们将介绍一些边缘计算中的常用术语。
-
电信边缘计算:由电信运营商管理的分布式计算,可能会扩展到网络边缘以外并扩展到客户边缘。客户可以运行低延迟的应用程序以及在靠近数据源的地方缓存或处理数据,以减少回程流量和成本。
-
本地部署边缘计算:由网络运营商管理的客户本地的计算资源,可用于应用程序和各种功能。这些功能运行在虚拟化环境中,作为基于云的跨分布式边缘架构。本地部署边缘计算可在本地保留敏感数据同时还能利用边缘云提供的弹性。
-
边缘云:在边缘计算之上的虚拟化基础架构和商业模型。边缘云具有云和本地服务器的优势,因为它具有灵活性和可扩展性,并且能够处理由于终端用户活动导致的工作负载突增。
-
私有云:通过私有网络向特定的用户提供计算服务。私有云还具备可伸缩性、敏捷性等优势,它与公有云的区别在于它能够通过内部云基础架构托管提供更高的安全性和数据隐私性。
-
网络边缘:这里的网络是指企业级别的网络(如无限LAN或数据中心),它能够连接到第三方网络(如互联网)。
边缘计算有什么作用?
对于远距离的位置来说,连接性和通信是十分具有挑战的,但是通过将信息本地化就能够降低延迟。而这也是边缘计算得以快速采纳的原因,它的引入让实时通信得以实现。在那些积极倡导计算的人们中间存在一个普遍的误区,那就是它们认为边缘计算这一技术纯粹是针对物联网嵌入式设备,但事实并非如此。无论信息源位于何处,边缘计算层都能够在其附近运行。
边缘计算中的每个单元都可能拥有单独的计算机、存储和网络系统。这些设备将管理网络交换、路由、负载均衡以及安全。由这些设备组成的完整系统将会成为多个来源的信息处理集中点。将通过事件处理检查数据点,以确定在什么位置进行信息分析。进而根据预先定义的规则对数据进行边缘处理或发送到附近的数据中心进行进一步分析。
世界上有两种类型的数据:热数据和冷数据。热数据可以帮助用户做出快速、自发的决策,这类数据不会被转移到数据中心,而是将其保存在边缘,这显示了边缘计算的两大特征:速度和敏捷性。而冷数据则要存储起来供以后检查或使用,其中会考虑到历史趋势。
边缘计算有哪些应用场景?
-
自动驾驶:对于自动驾驶的汽车而言,在人行横道前需要立即停车,这一决定需要汽车完成。而依赖远程服务器来决定这一行为的执行是十分不合理的。而利用了边缘计算技术的汽车则能够高效做出反应,因为他们可以直接相互通信,而不是先将关于事故、天气状况、交通状况的数据发送到远程服务器。边缘计算可以对此提供帮助。
-
医疗保健设备:健康监测及其他可穿戴医疗保健设备可以一直监测病人的慢性病情况。它能够在病人需要帮助的时候立即联系家属来挽救生命。而协助执行这一行为的机器人必须能够快速分析数据以确保提供安全、迅速、精确的救助。如果这些设备依赖于在云上进行分析,那么后果是不可想象的。
-
安全解决方案:由于安全监控系统必须要在数秒之内做出响应,因此它也将会得益于边缘计算技术。安全系统还需要识别潜在的威胁并实时对不正常的活动向用户发送警报。
-
零售广告:各类企业的定向投放的广告都是基于设备上的关键参数,比如人口统计信息。在这一情况下,边缘计算可以帮助用户保护隐私,它能够加密数据并保留源,而不是将不受保护的信息发送到云端。
-
智能语音设备:智能语音设备能够在本地分析语音指令以执行基本的操作,如开关灯、调节恒温器灯。即便无法连接到互联网,它也依旧能够执行这些操作。
-
视频会议:糟糕的视频画质、语音延迟、视频卡顿——这些都是由于依赖将数据传输到云端导致的。通过将视频会议软件的服务器端放置在离参会者更近的位置,可以减少上述质量问题。
边缘计算的优势
毫无疑问,企业一定是在了解到边缘计算能够提供的多项计算优势才选择采用它。
-
速度:借助数据分析的应用程序和工具并更接近信息的真实来源,以减少将信息从一个点传输到另一个点所需的物理空间和时间。边缘计算减少了延迟间隔,从而提高了整体的响应速度和质量。
-
不间断、可依赖的连接:边缘计算可以让本地微数据设备来处理和存储信息。最终,即便云供应商不断变化,企业也能够体验到IoT软件的可靠连接。除此之外,边缘计算还能够使IoT软件使用更少的带宽进行工作,并且还能在连接受限的情况下发挥其功能。这减少了企业关于数据和信息的顾虑。
-
低成本:供应商常常通过降低带宽需求来减少成本。因此一般会用本地化的设备作为数据中心的替代方案,并减少数据存储。
边缘计算的不足
-
边缘计算仅能处理信息的子集,会丢失原始数据。因此,企业需要考虑清楚什么程度的数据丢失是能够容忍的。
-
边缘计算可能提升攻击向量(attack vector)
-
边缘计算需要更多的辅助硬件。例如,IoT相机需要一个已集成的计算机通过万维网发送音频信息,此外还需要诸如面部识别算法等高级软件进行复杂的处理。
结 论
如今,企业为了保持竞争优势,正在为他们的业务不断寻找最佳实践。在这个时代中,技术不断迭代,它们为这个世界创造了新的机会,因此我们能够适应不断变化的世界,改善现在的条件。即使边缘计算是一个相对比较新的术语,但它为企业提供了巨大的机会,企业在使用它时,可以通过边缘计算网络的集群进行更快、更精确的数据处理。