 cs229
cs229- files
- img
- mind
- nlp-roadmap
- notebooks
- 图解数学
- 知识梳理
 Activation-Function.md
Activation-Function.md- AI-VNext.md
- algorithm.md
- Apple-Core-ML.md
- Audio.md
- awesome.md
- ChatGPT.md
- CNN.md
- CUDA-Install.md
- CV.md
- dataset.md
- deep-learning.md
- DeepLearning.md
- dotnet-ml.md
- Feature-Engineering.md
- GAN.md
- google-JAX.md
- High-reference-paper.md
- I-Know.md
- ICSharpCore.md
- image.md
- JupyterNotebook.md
- loss-function.md
- MCP.md
- Model-Selection.md
- multi-media.md
- NET Core with Jupyter Notebooks.md
- nlp.md
- Ollama.md
- person.md
- ppt素材.md
- pytorch.md
- README.md
- RNN.md
- robot.md
- tensorflow.md
- tools.md
- word2vec.md
- 书籍.md
- 有趣的应用.md
- 有趣的机器学习.md
- 模型汇总.md
- 生成模型和判别模型.md
- 线性回归和逻辑回归.md
Table of Contents
资料视频
https://github.com/Sakura-gh/ML-notes
https://www.bilibili.com/video/BV1JE411g7XF
挑战
https://www.bilibili.com/video/BV1P4411f7hK?p=3
- 照射角度
- 光照强度
- 形状改变
- 部分遮蔽
- 背景混入
硬train一发

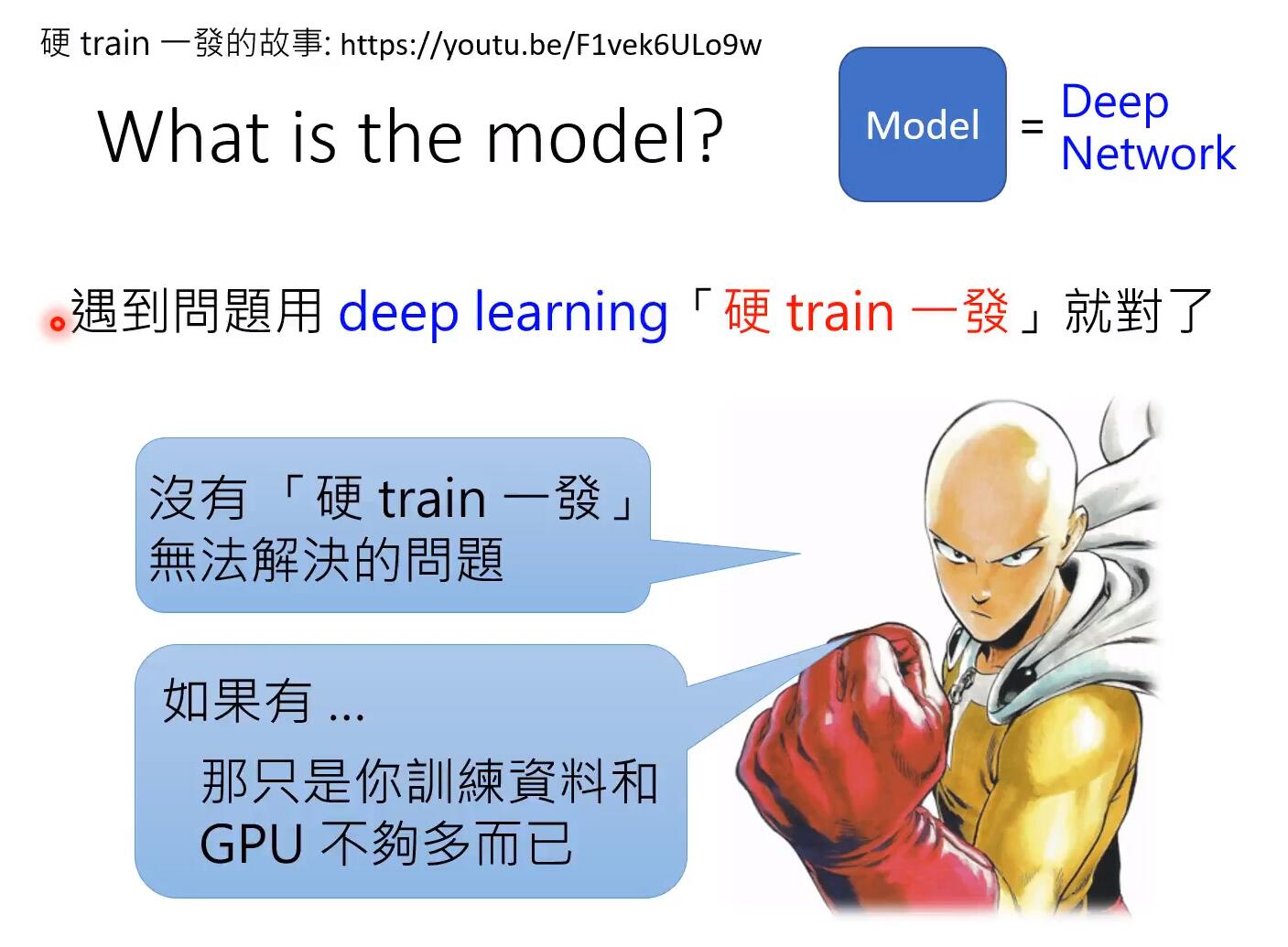
硬train一发 是从李宏毅老师的课程中看到的,感觉特别有意思,讲的是一个面试者被问编程输出Fizz Buzz的问题(其实类似yes/no的问题),然后他的回答是用神经网络训练了,结果是最终的正确率不够。
这个硬train一发 意思就是不管什么问题,都可以用神经网络来解决。
按照李老师说的原话:
硬train一发是一种信念,是一种梦想,是一种浪漫,是人类最原始的冲动,是亘古以来人类的目标。—— 李宏毅
而且,硬train一发需要三个必要条件:
- 一个问题,不要想太多,直接用deep learning train
- 开始train之前,旁边必须有一个有很不屑的表情的人说,“这个应该train不起来吧”
- train后出了结果,还要有人说,“我靠,这样居然也能train起来”
最初的来源: https://joelgrus.com/2016/05/23/fizz-buzz-in-tensorflow/
github: https://github.com/joelgrus/fizz-buzz-tensorflow
李老师的视频: https://www.youtube.com/watch?v=F1vek6ULo9w&feature=youtu.be
其它同学的代码
import numpy as np
from keras.layers.core import Dense,Activation,Dropout
from keras.models import Sequential
from keras.layers import Conv2D,MaxPooling2D,Flatten
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
x=np.zeros((5000,15),dtype=np.int)
y=np.zeros((5000,4),dtype=np.int)
for i in range(1,5001):
fizz=buzz=0
if not i%3:
fizz=1
if not i%5:
buzz=1
i-=1
if fizz and buzz:
y[i][2]=1
elif fizz and not buzz:
y[i][0]=1
elif not fizz and buzz:
y[i][1]=1
else:
y[i][3]=1
temp=i+1
for j in range(15):
x[i,j]=temp%2
temp //= 2
x_test=x[:1000]
y_test=y[:1000]
x_train=x[1000:]
y_train=y[1000:]
model=Sequential()
model.add(Dense(input_dim=15,units=1000))
model.add(Activation('relu'))
model.add(Dense(units=4))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=20,epochs=100)
result=model.evaluate(x_test,y_test,batch_size=1000)
print(f'精确率{result[1]}')
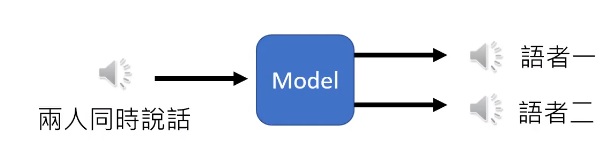
鸡尾酒会效应
鸡尾酒会效应(英语:cocktail party effect)是指人的一种听力选择能力,在这种情况下,注意力集中在某一个人的谈话之中而忽略背景中其他的对话或噪音。该效应揭示了人类听觉系统中令人惊奇的能力,即我们可以在噪声中谈话。
https://cnl.salk.edu/~tewon/Blind/blind_audio.html
http://www.aigei.com/item/ji_wei_jiu_hui.html
Independent component analysis (ICA)
用fastICA算法可以比较好地解决http://research.ics.tkk.fi/ica/fastica/
matlab:https://github.com/manityagi/cocktail/blob/master/main.m
特征工程
特征工程是机器学习,甚至是深度学习中最为重要的一部分,也是课本上最不愿意讲的一部分,特征工程往往是打开数据密码的钥匙,是数据科学中最有创造力的一部分,deep learning,作为一种强大的自动化特征工程工具,能够自动学习各种低级和高级的特征。
常见的特征选择分为三类方法:
- 过滤式(filter)
- 包裹式(wrapper)
- 嵌入式(embedding)
特征提取
一般常用的方法包括降维(PCA、ICA、LDA等)、图像方面的SIFT、Gabor、HOG等、文本方面的词袋模型、词嵌入模型等
- 类别特征
- one-hot encoding
- hash encoding
- label encoding
- count encoding
- label-count encoding
- target encoding
- category embedding
- Nan encoding
- polynomial encoding
- expansion encoding
- consolidation encoding
- 数值特征
- rounding
- binning
- scaling
- imputation
- interactions
- no linear encoding
- row statistics
- 时间特征
- 空间特征
- 自然语言处理
- 深度学习/NN
- Leakage
AutoML
其它
Google Research 2019 全面总结与展望
Google Research: Looking Back at 2019, and Forward to 2020 and Beyond