 files
files- img
- spark-ml-source-analysis
- yml
- 数据分析
 Amundsen.md
Amundsen.md- Apache-Beam.md
- Apache-Ignite.md
- Apache-Kudu.md
- Apache-Kylin.md
- Apache-kyuubi.md
- Apache-Zeppelin.md
- awesome.md
- BI-可视化.md
- CDC.md
- CDH.md
- DB.md
- ETL.md
- Flink-1.md
- Flink-Dev.md
- Flink-on-k8s.md
- Flink-SQL.md
- Flink-Stateful-Functions.md
- Flink.md
- go-hadoop.md
- Google-Dataflow-Model.md
- Hadoop-HDFS.md
- hadoop-spark-install.md
- Hadoop-Spark.md
- Hadoop.md
- Hbase.md
- openLooKeng.md
- PyFlink.md
- pyspark.md
- README.md
- spark-binlog.md
- Spark-Info.md
- spark-info2.md
- Spark-memory.md
- spark-ml.md
- Spark-on-Kubernetes.md
- spark-performance.md
- spark-posts.md
- spark-ppt素材.md
- spark-rdd.md
- spark-Structured-Streaming.md
- Spark-submit.md
- Spark-TFRecord.md
- spark-v3.0.md
- Spark-VS-Flink.md
- Spark.md
- spark2.md
- SparkSQL.md
- Structured-Streaming-VS-Flink.md
- tools.md
- 什么是Hadoop为什么是Spark.md
- 分析方法.md
- 推荐引擎.md
- 搜索指数.md
- 模型选择和训练-验证-测试集.md
- 用户画像.md
Table of Contents
[TOC]
一、Hadoop
Hadoop是一个开源的大数据框架,是一个分布式计算的解决方案。
Hadoop的两个核心解决了数据存储问题(HDFS分布式文件系统)和分布式计算问题(MapRe-duce)。
举例1:用户想要获取某个路径的数据,数据存放在很多的机器上,作为用户不用考虑在哪台机器上,HD-FS自动搞定。
举例2:如果一个100p的文件,希望过滤出含有Hadoop字符串的行。这种场景下,HDFS分布式存储,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,同时MapReduce分布式计算可以将大数据量的作业先分片计算,最后汇总输出。
1. 什么是Hadoop
- Apache™ Hadoop® project 生产出的用于高可靠、可扩展、分布式计算的开源软件,它允许通过集群的方式使用简单的编程模型分布式处理大数据,它可以从单一的服务器扩展到成千上万的机器,每一台机器都能提供本地计算和存储。Hadoop认为集群中节点故障为常态,它可以自动检测和处理故障节点,所以它不依赖硬件来提供高可用性。
- 简单的说,我们可以用Hadoop分布式存储大量数据,然后根据自己的业务对海量数据进行分布式计算。例如:
- 淘宝网昨天24小时的用户访问量折线图,不同地区、不同时段、不同终端
- 中国
- Apache™ Hadoop® project 包含的模块
- Hadoop Common :The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): 高吞吐分布式文件系统
- Hadoop YARN: 作业(Job)安排和资源调度平台/框架
- Hadoop MapReduce: 运行在yarn上的大数据并行计算模型
- 其他相关project
- Ambari
- HBase
- Hive
- Spark
- Zookeeper
- ...
- HDF5 (Hierarchical Data Format)
2. Hadoop产生背景
- Doug Cutting是Lucene、Nutch 、Hadoop等项目的发起人
- Hadoop最早起源于Nutch。Nutch的设计目的是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题:如何解决数十亿网页的存储和索引问题。
- 2003、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
- 分布式文件系统(GFS),可用于处理海量网页存储
- 分布式计算框架(MapReduce),可用于海量网页的索引计算问题
- 谷歌在03到06年间连续发表了三篇很有影响力的文章,分别是03年SOSP的GFS,04年OSDI的MapReduce,和06年OSDI的BigTable。SOSP和OSDI都是操作系统领域的顶级会议,在计算机学会推荐会议里属于A类。SOSP在单数年举办,而OSDI在双数年举办。
- Nutch开发人员完成了相应的开源实现HDFS和MapReduce,并从Nutch中剥离成为独立项目Hadoop,直到2008年,Hadoop成为Apache顶级项目,之后快速发展。
- 到现在hadoop已经形成了完善的生态圈
Ceph 分布式文件系统
3. Hadoop架构
- 分布式架构简介
-
单机的问题
- 存储能力有限
- 计算能力有限
- 有单点故障
- ...
-
分布式架构解决了单机问题
-
经典分布式主从架构
- Master(老大)负责管理,可以有多个,防止单节点故障发生
- Slave(小弟)负责干活,有多个,可以动态添加删除
-
Hadoop2.0架构
- HDFS:NameNode(老大),DateNode(小弟)
- YARN:ResourceManager(老大),NodeManager(小弟)
4. Hadoop生态
-
Hadoop生态圈:
-
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
-
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。
-
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
-
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
-
Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
-
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
-
HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
-
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽然奇怪的组合也能工作,但是未必是最佳选择。
-
大数据,首先你要能存的下大数据。传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,但是你看到的是一个文件系统而不是很多文件系统。比如你说我要获取/hdfs/tmp/file1的数据,你引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。你作为用户,不需要知道这些,就好比在单机上你不关心文件分散在什么磁道什么扇区一样。HDFS为你管理这些数据。
-
存的下数据之后,你就开始考虑怎么处理数据。虽然HDFS可以为你整体管理不同机器上的数据,但是这些数据太大了。一台机器读取成T上P的数据(很大的数据哦,比如整个东京热有史以来所有高清电影的大小甚至更大),一台机器慢慢跑也许需要好几天甚至好几周。对于很多公司来说,单机处理是不可忍受的,比如微博要更新24小时热博,它必须在24小时之内跑完这些处理。那么我如果要用很多台机器处理,我就面临了如何分配工作,如果一台机器挂了如何重新启动相应的任务,机器之间如何互相通信交换数据以完成复杂的计算等等。这就是MapReduce / Tez / Spark的功能。MapReduce是第一代计算引擎,Tez和Spark是第二代。MapReduce的设计,采用了很简化的计算模型,只有Map和Reduce两个计算过程(中间用Shuffle串联),用这个模型,已经可以处理大数据领域很大一部分问题了。
-
那什么是Map什么是Reduce?考虑如果你要统计一个巨大的文本文件存储在类似HDFS上,你想要知道这个文本里各个词的出现频率。你启动了一个MapReduce程序。Map阶段,几百台机器同时读取这个文件的各个部分,分别把各自读到的部分分别统计出词频,产生类似(hello, 12100次),(world,15214次)等等这样的Pair(我这里把Map和Combine放在一起说以便简化);这几百台机器各自都产生了如上的集合,然后又有几百台机器启动Reduce处理。Reducer机器A将从Mapper机器收到所有以A开头的统计结果,机器B将收到B开头的词汇统计结果(当然实际上不会真的以字母开头做依据,而是用函数产生Hash值以避免数据串化。因为类似X开头的词肯定比其他要少得多,而你不希望数据处理各个机器的工作量相差悬殊)。然后这些Reducer将再次汇总,(hello,12100)+(hello,12311)+(hello,345881)= (hello,370292)。每个Reducer都如上处理,你就得到了整个文件的词频结果。这看似是个很简单的模型,但很多算法都可以用这个模型描述了。Map+Reduce的简单模型很黄很暴力,虽然好用,但是很笨重。第二代的Tez和Spark除了内存Cache之类的新feature,本质上来说,是让Map/Reduce模型更通用,让Map和Reduce之间的界限更模糊,数据交换更灵活,更少的磁盘读写,以便更方便地描述复杂算法,取得更高的吞吐量。
-
有了MapReduce,Tez和Spark之后,程序员发现,MapReduce的程序写起来真麻烦。他们希望简化这个过程。这就好比你有了汇编语言,虽然你几乎什么都能干了,但是你还是觉得繁琐。你希望有个更高层更抽象的语言层来描述算法和数据处理流程。于是就有了Pig和Hive。Pig是接近脚本方式去描述MapReduce,Hive则用的是SQL。它们把脚本和SQL语言翻译成MapReduce程序,丢给计算引擎去计算,而你就从繁琐的MapReduce程序中解脱出来,用更简单更直观的语言去写程序了。
-
有了Hive之后,人们发现SQL对比Java有巨大的优势。一个是它太容易写了。刚才词频的东西,用SQL描述就只有一两行,MapReduce写起来大约要几十上百行。而更重要的是,非计算机背景的用户终于感受到了爱:我也会写SQL!于是数据分析人员终于从乞求工程师帮忙的窘境解脱出来,工程师也从写奇怪的一次性的处理程序中解脱出来。大家都开心了。Hive逐渐成长成了大数据仓库的核心组件。甚至很多公司的流水线作业集完全是用SQL描述,因为易写易改,一看就懂,容易维护。
-
自从数据分析人员开始用Hive分析数据之后,它们发现,Hive在MapReduce上跑,真几把慢!流水线作业集也许没啥关系,比如24小时更新的推荐,反正24小时内跑完就算了。但是数据分析,人们总是希望能跑更快一些。比如我希望看过去一个小时内多少人在充气娃娃页面驻足,分别停留了多久,对于一个巨型网站海量数据下,这个处理过程也许要花几十分钟甚至很多小时。而这个分析也许只是你万里长征的第一步,你还要看多少人浏览了跳蛋多少人看了拉赫曼尼诺夫的CD,以便跟老板汇报,我们的用户是猥琐男闷骚女更多还是文艺青年/少女更多。你无法忍受等待的折磨,只能跟帅帅的工程师蝈蝈说,快,快,再快一点!
-
于是Impala,Presto,Drill(交互式查询引擎)诞生了(当然还有无数非著名的交互SQL引擎,就不一一列举了)。三个系统的核心理念是,MapReduce引擎太慢,因为它太通用,太强壮,太保守,我们SQL需要更轻量,更激进地获取资源,更专门地对SQL做优化,而且不需要那么多容错性保证(因为系统出错了大不了重新启动任务,如果整个处理时间更短的话,比如几分钟之内)。这些系统让用户更快速地处理SQL任务,牺牲了通用性稳定性等特性。如果说MapReduce是大砍刀,砍啥都不怕,那上面三个就是剔骨刀,灵巧锋利,但是不能搞太大太硬的东西。
-
这些系统,说实话,一直没有达到人们期望的流行度。因为这时候又两个异类被造出来了。他们是Hive on Tez / Spark和SparkSQL。它们的设计理念是,MapReduce慢,但是如果我用新一代通用计算引擎Tez或者Spark来跑SQL,那我就能跑的更快。而且用户不需要维护两套系统。这就好比如果你厨房小,人又懒,对吃的精细程度要求有限,那你可以买个电饭煲,能蒸能煲能烧,省了好多厨具。
-
上面的介绍,基本就是一个数据仓库的构架了。底层HDFS,上面跑MapReduce/Tez/Spark,在上面跑Hive,Pig。或者HDFS上直接跑Impala,Drill,Presto。这解决了中低速数据处理的要求。
-
那如果我要更高速的处理呢?
-
如果我是一个类似微博的公司,我希望显示不是24小时热博,我想看一个不断变化的热播榜,更新延迟在一分钟之内,上面的手段都将无法胜任。于是又一种计算模型被开发出来,这就是Streaming(流)计算。Storm是最流行的流计算平台。流计算的思路是,如果要达到更实时的更新,我何不在数据流进来的时候就处理了?比如还是词频统计的例子,我的数据流是一个一个的词,我就让他们一边流过我就一边开始统计了。流计算很牛逼,基本无延迟,但是它的短处是,不灵活,你想要统计的东西必须预先知道,毕竟数据流过就没了,你没算的东西就无法补算了。因此它是个很好的东西,但是无法替代上面数据仓库和批处理系统。
-
还有一个有些独立的模块是KV Store,比如Cassandra,HBase,MongoDB以及很多很多很多很多其他的(多到无法想象)。所以KV Store就是说,我有一堆键值,我能很快速滴获取与这个Key绑定的数据。比如我用身份证号,能取到你的身份数据。这个动作用MapReduce也能完成,但是很可能要扫描整个数据集。而KV Store专用来处理这个操作,所有存和取都专门为此优化了。从几个P的数据中查找一个身份证号,也许只要零点几秒。这让大数据公司的一些专门操作被大大优化了。比如我网页上有个根据订单号查找订单内容的页面,而整个网站的订单数量无法单机数据库存储,我就会考虑用KV Store来存。KV Store的理念是,基本无法处理复杂的计算,大多没法JOIN,也许没法聚合,没有强一致性保证(不同数据分布在不同机器上,你每次读取也许会读到不同的结果,也无法处理类似银行转账那样的强一致性要求的操作)。但是丫就是快。极快。
-
每个不同的KV Store设计都有不同取舍,有些更快,有些容量更高,有些可以支持更复杂的操作。必有一款适合你。
-
除此之外,还有一些更特制的系统/组件,比如Mahout是分布式机器学习库,Protobuf是数据交换的编码和库,ZooKeeper是高一致性的分布存取协同系统,等等。
-
有了这么多乱七八糟的工具,都在同一个集群上运转,大家需要互相尊重有序工作。所以另外一个重要组件是,调度系统。现在最流行的是Yarn。你可以把他看作中央管理,好比你妈在厨房监工,哎,你妹妹切菜切完了,你可以把刀拿去杀鸡了。只要大家都服从你妈分配,那大家都能愉快滴烧菜。
-
你可以认为,大数据生态圈就是一个厨房工具生态圈。为了做不同的菜,中国菜,日本菜,法国菜,你需要各种不同的工具。而且客人的需求正在复杂化,你的厨具不断被发明,也没有一个万用的厨具可以处理所有情况,因此它会变的越来越复杂。
-
-
Hadoop Spark Storm 区别?
-
从计算模型上:Hadoop是批处理型,Spark和Storm是流处理型
-
从处理时延上:Hadoop数分钟-数小时,Spark秒级,Sotrm毫秒级
-
从吞吐量上:Hadoop>Spark>Storm
-
从容错性上:Hadoop>Storm>Spark
-
对于Hadoop来说
- Spark Storm能做的它都能做,但就是处理时延大
- 如果处理较大文件且不需要实时性必然选择Hadoop。
- 如果处理的都是一些小文件且需要需要一定实时性选择Spark(准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理)
- 如果需要非常强的实时性选择Storm(纯实时,来一条数据,处理一条数据,常见消息来源MQ)
-
对于Storm来说:
- 建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
- 此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
- 如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
- 如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
-
对于Spark Streaming来说:
- 如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
- 考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性
-
Spark Streaming与Storm的优劣分析
- 事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
- Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。
- 事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、动态调整并行度等特性,都要比Spark Streaming更加优秀。
- Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
-
二、Hadoop特点
优点
1、支持超大文件。HDFS存储的文件可以支持TB和PB级别的数据。
2、检测和快速应对硬件故障。数据备份机制,NameNode通过心跳机制来检测DataNode是否还存在。
3、高扩展性。可建构在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,NameNode也可以感知,将数据分发和备份到相应的节点上。
4、成熟的生态圈。借助开源的力量,围绕Hadoop衍生的一些小工具。
缺点
1、不能做到低延迟。高数据吞吐量做了优化,牺牲了获取数据的延迟。
2、不适合大量的小文件存储。
3、文件修改效率低。HDFS适合一次写入,多次读取的场景。
Hadoop能干什么
- 大数据存储: 分布式存储
- 日志处理: 擅长日志分析
- ETL: 数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 机器学习: 比如Apache Mahout项目
- 搜索引擎: Hadoop + lucene实现
- 数据挖掘: 目前比较流行的广告推荐,个性化广告推荐
Hadoop是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
三、HDFS介绍
1、HDFS框架分析
HDFS是Master和Slave的主从结构。主要由Name-Node、Secondary NameNode、DataNode构成。
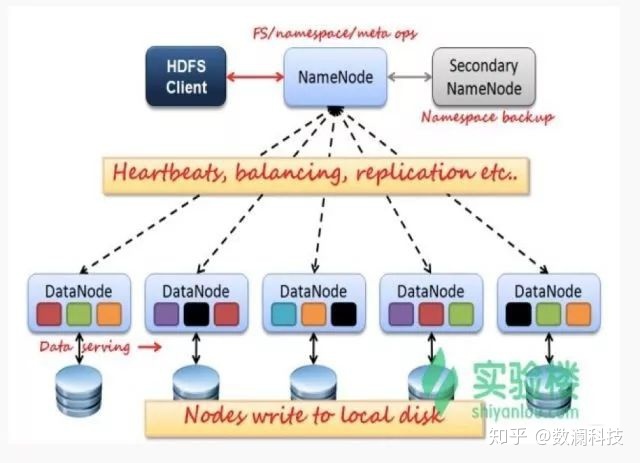
NameNode
管理HDFS的名称空间和数据块映射信存储元数据与文件到数据块映射的地方。
如果NameNode挂掉了,文件就会无法重组,怎么办?有哪些容错机制?
Hadoop可以配置成HA即高可用集群,集群中有两个NameNode节点,一台active主节点,另一台stan-dby备用节点,两者数据时刻保持一致。当主节点不可用时,备用节点马上自动切换,用户感知不到,避免了NameNode的单点问题。
Secondary NameNode
辅助NameNode,分担NameNode工作,紧急情况下可辅助恢复NameNode。
DataNode
Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode。
2、HDFS文件读写
文件按照数据块的方式进行存储在DataNode上,数据块是抽象块,作为存储和传输单元,而并非整个文件。
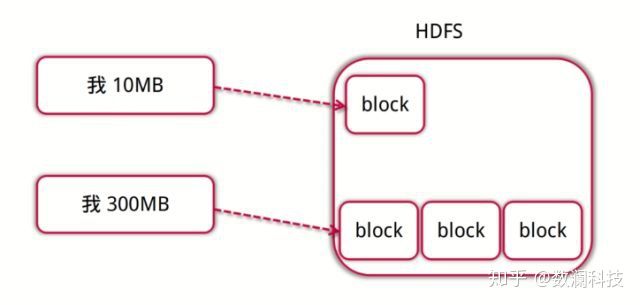
文件为什么要按照块来存储呢?
首先屏蔽了文件的概念,简化存储系统的设计,比如100T的文件大于磁盘的存储,需要把文件分成多个数据块进而存储到多个磁盘;为了保证数据的安全,需要备份的,而数据块非常适用于数据的备份,进而提升数据的容错能力和可用性。
数据块大小设置如何考虑?
文件数据块大小如果太小,一般的文件也就会被分成多个数据块,那么在访问的时候也就要访问多个数据块地址,这样效率不高,同时也会对NameNode的内存消耗比较严重;数据块设置得太大的话,对并行的支持就不太好了,同时系统如果重启需要加载数据,数据块越大,系统恢复就会越长。
HDFS文件读流程
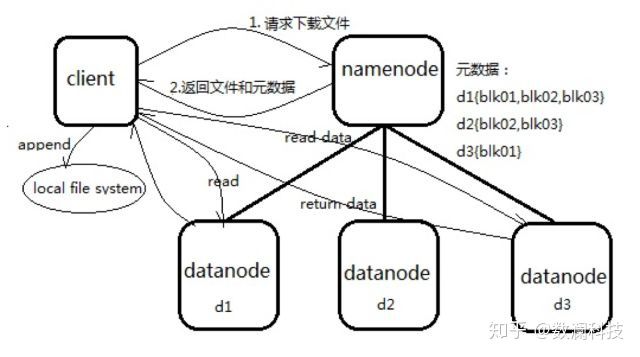
1、向NameNode通信查询元数据(block所在的DataNode节点),找到文件块所在的DataNode服务器。
2、挑选一台DataNode(就近原则,然后随机)服务器,请求建立socket流。
3、DataNode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4、客户端已packet为单位接收,现在本地缓存,然后写入目标文件,后面的block块就相当于是append到前面的block块最后合成最终需要的文件。
HDFS文件写流程
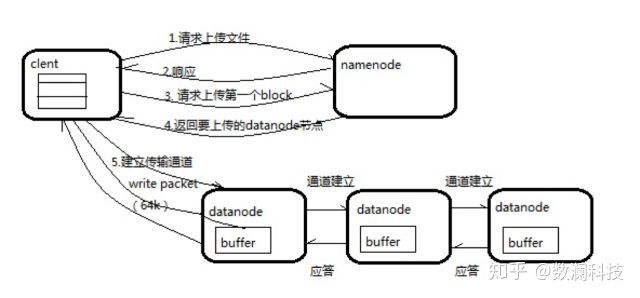
-
向NameNode通信请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
-
NameNode返回确认可以上传。
-
client会先对文件进行切分,比如一个block块128m,文件有300m就会被切分成3个块,一个128m、一个128m、一个44m。请求第一个block该传输到哪些DataNode服务器上。
-
NameNode返回DataNode的服务器。
-
client请求一台DataNode上传数据,第一个DataNode收到请求会继续调用第二个DataNode,然后第二个调用第三个DataNode,将整个通道建立完成,逐级返回客户端。
-
client开始往A上传第一个block,当然在写入的时候DataNode会进行数据校验,第一台DataNode收到后就会传给第二台,第二台传给第三台。
-
当一个block传输完成之后,client再次请求NameNode上传第二个block的服务器。
四、MapReduce介绍
1、概念
MapReduce是一种编程模型,是一种编程方法,是抽象的理论,采用了分而治之的思想。MapReduce框架的核心步骤主要分两部分,分别是Map和Reduce。每个文件分片由单独的机器去处理,这就是Map的方法,将各个机器计算的结果汇总并得到最终的结果,这就是Reduce的方法。
2、工作流程
向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
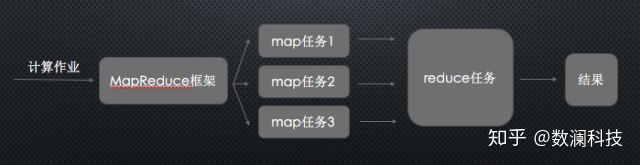
3、运行MapReduce示例
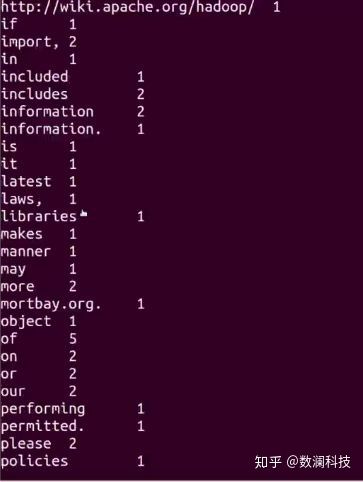
运行Hadoop自带的MapReduce经典示例Word-count,统计文本中出现的单词及其次数。首先将任务提交到Hadoop框架上。

查看MapReduce运行结束后的输出文件目录及结果内容。

可以看到统计单词出现的次数结果
五、Hadoop安装
墙裂推荐:史上最详细的Hadoop环境搭建https://blog.csdn.net/hliq5399/article/details/78193113/