 files
files- img
- spark-ml-source-analysis
- yml
- 数据分析
 Amundsen.md
Amundsen.md- Apache-Beam.md
- Apache-Ignite.md
- Apache-Kudu.md
- Apache-Kylin.md
- Apache-kyuubi.md
- Apache-Zeppelin.md
- awesome.md
- BI-可视化.md
- CDC.md
- CDH.md
- DB.md
- ETL.md
- Flink-1.md
- Flink-Dev.md
- Flink-on-k8s.md
- Flink-SQL.md
- Flink-Stateful-Functions.md
- Flink.md
- go-hadoop.md
- Google-Dataflow-Model.md
- Hadoop-HDFS.md
- hadoop-spark-install.md
- Hadoop-Spark.md
- Hadoop.md
- Hbase.md
- openLooKeng.md
- PyFlink.md
- pyspark.md
- README.md
- spark-binlog.md
- Spark-Info.md
- spark-info2.md
- Spark-memory.md
- spark-ml.md
- Spark-on-Kubernetes.md
- spark-performance.md
- spark-posts.md
- spark-ppt素材.md
- spark-rdd.md
- spark-Structured-Streaming.md
- Spark-submit.md
- Spark-TFRecord.md
- spark-v3.0.md
- Spark-VS-Flink.md
- Spark.md
- spark2.md
- SparkSQL.md
- Structured-Streaming-VS-Flink.md
- tools.md
- 什么是Hadoop为什么是Spark.md
- 分析方法.md
- 推荐引擎.md
- 搜索指数.md
- 模型选择和训练-验证-测试集.md
- 用户画像.md
Table of Contents
Spark-TFRecord: Spark将全面支持TFRecord
TFRecord
正常情况下我们训练文件夹经常会生成 train, test 或者val文件夹,
这些文件夹内部往往会存着成千上万的图片或文本等文件,这些文件被散列存着,这样不仅占用磁盘空间,并且再被一个个读取的时候会非常慢,繁琐。
占用大量内存空间(有的大型数据不足以一次性加载)。此时我们TFRecord格式的文件存储形式会很合理的帮我们存储数据。
TFRecord内部使用了“Protocol Buffer”二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。
而且当我们的训练数据量比较大的时候,可以将数据分成多个TFRecord文件,来提高处理效率。
# TFRecord生成器
writer = tf.python_io.TFRecordWriter(record_path)
writer.write(tf_example.SerializeToString())
writer.close()
TFRecord - TensorFlow 官方推荐的数据格式 到后来的 TensorFlow的原生格式
Spark-TFRecord简介
在机器学习领域,Apache Spark 由于其支持 SQL 类型的操作以及高效的数据处理,被广泛的用于数据预处理流程,同时 TensorFlow 作为广受欢迎的深度学习框架被广泛的用于模型训练。尽管两个框架有一些共同支持的数据格式,但是,作为 TFRecord—TensorFlow 的原生格式,并没有被 Spark 完全支持。尽管之前有过一些尝试,试图解决两个系统之间的差异(比如 Spark-TensorFlow-Connector),但是现有的实现都缺少很多 Spark 支持的重要特性。
本文中,我们将介绍 Spark 的一个新的数据源,Spark-TFRecord。Spark-TFRecord 的目的是提供在Spark中对原生的 TensorFlow 格式进行完全支持。本项目的目的是将TFRecord 作为Spark数据源社区中的第一类公民,类似于 Avro,JSON,Parquet等。Spark-TFRecord 不仅仅提供简单的功能支持,比如 Data Frame的读取、写入,还支持一些高阶功能,比如ParititonBy。使用 Spark-TFRecord 将会使数据处理流程与训练工程完美结合。
LinkedIn 内部 Spark 和 TensorFlow 都被广泛的使用。Spark 被用于数据处理、训练数据预处理流程中。Spark 同时也是数据分析的领先工具。随着原来越多的商业部门使用深度学习模型,TensorFlow 成为了模型训练和模型服务的主流工具。开源的TensorFlow 模型使用 TFRecord 作为数据格式,而LinkedIn 内部大部分使用 Avro 格式。为了模型训练,我们或者修改代码使模型训练能够读取avro格式,或者将avro格式的datasets转化为TFRecord。Spark-TFRecod主要是解决后者,即将不同格式转化为TFRecord。
现有的项目和之前的尝试
在 Spark-TFRecord 项目之前,社区提供 Spark-TensorFlow-Connector , 在 Spark 中读写 TFRecord 。Spark-TensorFlow-Connector 是 TensorFlow 生态圈的一部分,并且是由 DataBricks,spark 的创始公司提供。尽管 Spark-TensorFlow-Connector 提供基本的读写功能,但是我们在LinkedIn的使用中发现了两个问题。首先,它基于RelationProvider接口。这个接口主要用于Spark与数据库连接,磁盘读写操作都是由数据库来支持。然而 Spark-TensorFlow-Connector 的使用场景是磁盘IO,而不是连接数据库,这块接口需要开发者自己实现 RelationProvider 来支持IO操作。这就是为什么Spark-TensorFlow-Connector 大量代码是用于不同的磁盘读写场景。
此外,Spark-TensorFlow-Connector 缺少一些 Spark支持的重要功能,比如 PartitionBy 用于将dataset 根据不同列进行分片。我们发现这个功能在LinkedIn 中对于模型训练非常重要,提供训练过程中根据实体IDs进行切分进行分布式训练。这个功能在TensorFlow 社区中也是高需求。
Spark-TFRrecord 为了解决上述问题,实现了FileFormat 接口,其他的原生格式比如 Avro,Parquet 等也实现了该接口。使用该接口后,TFRecord 就获取了所有的 DataFrame 和 DataSet 的I/O API,包括之前说的 PartitionBy 功能。此外,之后的 Spark I/O接口的功能增强也能够自动获取到。
设计
我们起初考虑对 Spark-TensorFlow-Connector 打补丁的方式去获取 PartitionBy 功能。检查过源码后,我们发现 Spark-TensorFlow-Connector 使用的RelationProvider接口,是用于连接Spark与SQL数据库的,不适用于 TensorFlow 场景。然后并没有一个简单解决方式去解决 RelationProvider 并不提供磁盘I/O操作这一问题。于是,我们决定采取了不同的方式,我们实现了FileFormat,FileFormat是用来实现底层的基于文件的I/O操作。实现这一功能对LinkedIn的场景是非常有用的,我们的datasets基本上都是直接读写磁盘。
下图展示了各个模块
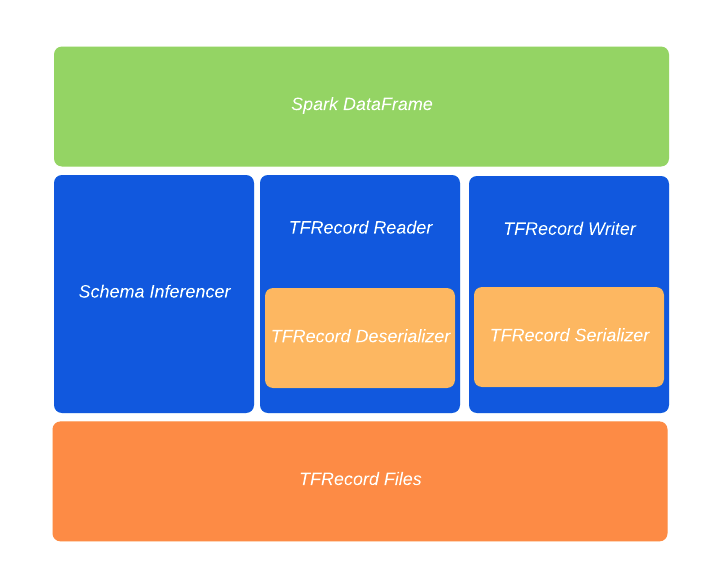
每个模块作用如下:
Schema Inferencer: 用于将Spark的数据类型推测为TFRecord的数据类型,我们复用了很多Spark-Tensorflow-Connector功能。
TFRecord Reader: 读取磁盘中TFRecord文件并使用反序列化器将TFRecord转换为Spark的InternalRow数据结构。
TFRecord Writer:将Spark的InternalRow数据结构通过序列化器转化为TFRecord格式并保存至磁盘。我们使用TensorFlow Hadoop库的写入器。
TFRecord Deserializer: 反序列化器,将TFRecord转化为Spark InternalRow。
TFRecord Serializer: 序列化器,将Spark InternalRow转化为TFRecord。
如何使用Spark-TFRecord
Spark-TFRecord与Spark-TensorFlow-Connector完全后向兼容。迁移十分方便,只需要加入spark-tfrecord jar包并且指定数据格式为“tfrecord”。下面的例子显示了如何使用Spark-TFRecord去读取倾斜和partition TFRecord文件。更多的例子可以参照github仓库。
// launch spark-shell with the following command:
// SPARK_HOME/bin/spark-shell --jar target/spark-tfrecord_2.11-0.1.jar
import org.apache.spark.sql.SaveMode
val df = Seq((8, "bat"),(8, "abc"), (1, "xyz"), (2, "aaa")).toDF("number", "word")
df.show
// scala> df.show
// +------+----+
// |number|word|
// +------+----+
// | 8| bat|
// | 8| abc|
// | 1| xyz|
// | 2| aaa|
// +------+----+
val tf_output_dir = "/tmp/tfrecord-test"
// dump the tfrecords to files.
df.repartition(3, col("number")).write.mode(SaveMode.Overwrite).partitionBy("number").format("tfrecord").option("recordType", "Example").save(tf_output_dir)
// ls /tmp/tfrecord-test
// _SUCCESS number=1 number=2 number=8
// read back the tfrecords from files.
val new_df = spark.read.format("tfrecord").option("recordType", "Example").load(tf_output_dir)
new_df.show
// scala> new_df.show
// +----+------+
// |word|number|
// +----+------+
// | bat| 8|
// | abc| 8|
// | xyz| 1|
// | aaa| 2|
总结
Spark-TFRecord使得Record可以作为Spark 数据格式的一等公民与其他数据格式一起使用。包含了所有dataframe API的功能,比如读、写、分区等。目前我们仅限于schemas符合Spark-Tensorflow-Connector要求。未来的工作将会提供更复杂的schemas支持。