 files
files- img
- spark-ml-source-analysis
- yml
- 数据分析
 Amundsen.md
Amundsen.md- Apache-Beam.md
- Apache-Ignite.md
- Apache-Kudu.md
- Apache-Kylin.md
- Apache-kyuubi.md
- Apache-Zeppelin.md
- awesome.md
- BI-可视化.md
- CDC.md
- CDH.md
- DB.md
- ETL.md
- Flink-1.md
- Flink-Dev.md
- Flink-on-k8s.md
- Flink-SQL.md
- Flink-Stateful-Functions.md
- Flink.md
- go-hadoop.md
- Google-Dataflow-Model.md
- Hadoop-HDFS.md
- hadoop-spark-install.md
- Hadoop-Spark.md
- Hadoop.md
- Hbase.md
- openLooKeng.md
- PyFlink.md
- pyspark.md
- README.md
- spark-binlog.md
- Spark-Info.md
- spark-info2.md
- Spark-memory.md
- spark-ml.md
- Spark-on-Kubernetes.md
- spark-performance.md
- spark-posts.md
- spark-ppt素材.md
- spark-rdd.md
- spark-Structured-Streaming.md
- Spark-submit.md
- Spark-TFRecord.md
- spark-v3.0.md
- Spark-VS-Flink.md
- Spark.md
- spark2.md
- SparkSQL.md
- Structured-Streaming-VS-Flink.md
- tools.md
- 什么是Hadoop为什么是Spark.md
- 分析方法.md
- 推荐引擎.md
- 搜索指数.md
- 模型选择和训练-验证-测试集.md
- 用户画像.md
Table of Contents
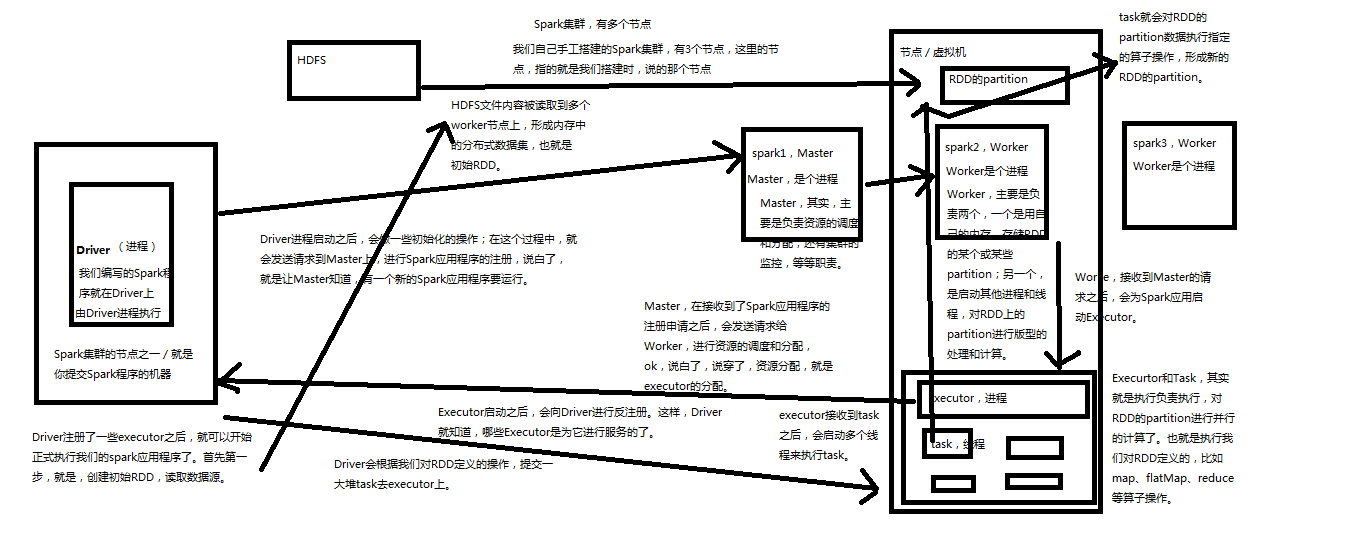
spark架构原理
1、Driver,启动之后执行一些初始化操作,然后向Master进行注册,让master知道有一个spark应用程序要执行。在Executor反向注册以后,就可以开始正式执行spark程序,首先第一步创建初始RDD,读取数据源。从HDFS文件内容中读取数据,分布到work节点上,形成内存中的分布式数据集也就是初始RDD。Driver会根据我们对RDD定义的操作,提交一堆task去excecutor上去
2、Master,master主要复制资源调度和集群监控等功能。它收到Driver发送的请求后,发送请求给work,进行资源分配就是分配一些executor
3、Worker,主要负责存储rdd的一些和部分partition,另外一个就是启动其他进程和线程对partition进行版型处理和计算。Executor启动后会反向向Driver进行注册,这样Driver就知道那些executor为他进行服务
4、Executor,executor接收到多个task后会启动多个线程来执行task
5、Task task就会对RDD的partition数据执行指定的算子操作,形成新的RDD的partition
RDD概念
Resilient Distributed Datasets 弹性分布式数据集,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(transformation操作)而创建。RDD可看作一个spark的对象,它本身存在于内存中,如对文件计算是一个RDD,等。
一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency;若多个Child RDD分区都可以依赖,则称之为wide dependency。
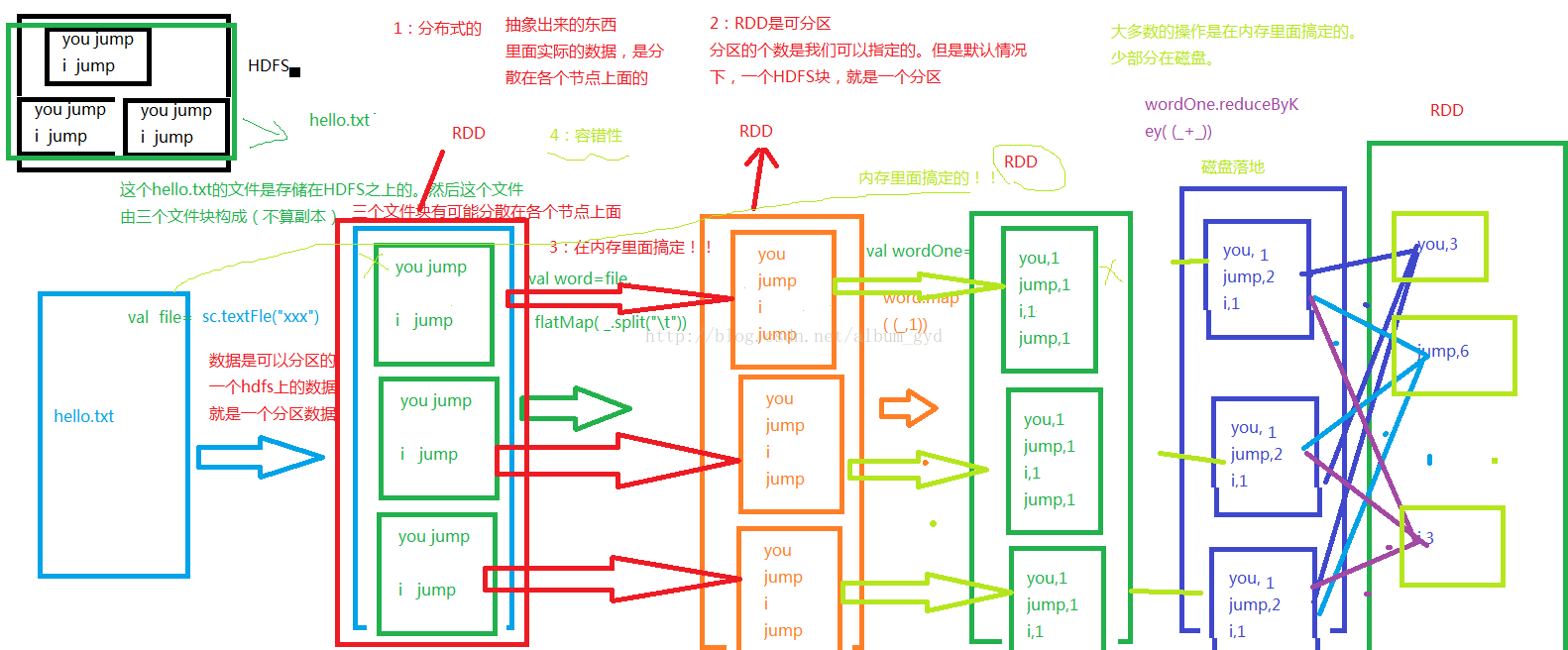
RDD抽象出来的东西里面实际的数据,是分散在各个节点上面的,RDD可分区,分区的个数是我们可以指定的。但是默认情况下,一个hdfs块就是一个分区。
且大部分操作在内存里面,少部分在磁盘,例如reduceByKey操作,就需要放在磁盘,为了保证数据的安全性,然后再从磁盘被读取出到内存上面。容错性好。
RDD如何保障数据处理效率?
RDD提供了两方面的特性persistence和patitioning,用户可以通过persist与patitionBy函数来控制RDD的这两个方面。RDD的分区特性与并行计算能力(RDD定义了parallerize函数),使得Spark可以更好地利用可伸缩的硬件资源。若将分区与持久化二者结合起来,就能更加高效地处理海量数据。例如:
input.map(parseArticle _).partitionBy(partitioner).cache()
partitionBy函数需要接受一个Partitioner对象,如:
val partitioner = new HashPartitioner(sc.defaultParallelism)
RDD本质上是一个内存数据集,在访问RDD时,指针只会指向与操作相关的部分。例如存在一个面向列的数据结构,其中一个实现为Int的数组,另一个实现为Float的数组。如果只需要访问Int字段,RDD的指针可以只访问Int数组,避免了对整个数据结构的扫描。
RDD将操作分为两类:transformation与action。无论执行了多少次transformation操作,RDD都不会真正执行运算,只有当action操作被执行时,运算才会触发。而在RDD的内部实现机制中,底层接口则是基于迭代器的,从而使得数据访问变得更高效,也避免了大量中间结果对内存的消耗。
在实现时,RDD针对transformation操作,都提供了对应的继承自RDD的类型,例如map操作会返回MappedRDD,而flatMap则返回FlatMappedRDD。当我们执行map或flatMap操作时,不过是将当前RDD对象传递给对应的RDD对象而已。例如:
def map[U: ClassTag](f: T => U): RDD[U] = new MappedRDD(this,sc.clean(f))
这些继承自RDD的类都定义了compute函数。该函数会在action操作被调用时触发,在函数内部是通过迭代器进行对应的转换操作:
private[spark]
class MappedRDD[U: ClassTag, T: ClassTag](prev: RDD[T], f: T => U)
extends RDD[U](prev) {
override def getPartitions:Array[Partition] = firstParent[T].partitions
override def compute(split:Partition, context: TaskContext) =
firstParent[T].iterator(split, context).map(f)
}
总结:
RDD是Spark的核心,也是整个Spark的架构基础。它的特性可以总结如下:
它是不变的数据结构存储
它是支持跨集群的分布式数据结构
可以根据数据记录的key对结构进行分区
提供了粗粒度的操作,且这些操作都支持分区
它将数据存储在内存中,从而提供了低延迟性
spark-spark RDD的创建
进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD。该RDD中,通常就代表和包含了Spark应用程序的输入源数据。然后在创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行转换,来获取其他的RDD。
Spark Core提供了三种创建RDD的方式,包括:使用程序中的集合创建RDD;使用本地文件创建RDD;使用HDFS文件创建RDD。
1、使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程。sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
2、使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件。集群上运行时需要所有集群上都有该文件 sc.textFile("C://Users//Administrator//Desktop//spark.txt");
3、使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作。sc.textFile("hdfs://spark1:9000/spark.txt");
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用SparkContext的parallelize()方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。相当于是,集合中的部分数据会到一个节点上,而另一部分数据会到其他节点上。然后就可以用并行的方式来操作这个分布式数据集合,即RDD。
调用parallelize()时,有一个重要的参数可以指定,就是要将集合切分成多少个partition。Spark会为每一个partition运行一个task来进行处理。Spark官方的建议是,为集群中的每个CPU创建2~4个partition。Spark默认会根据集群的情况来设置partition的数量。但是也可以在调用parallelize()方法时,传入第二个参数,来设置RDD的partition数量。比如parallelize(arr, 10)
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的,比如说HDFS、Cassandra、HBase以及本地文件。通过调用SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD。
有几个事项是需要注意的:
1、如果是针对本地文件的话,如果是在windows上本地测试,windows上有一份文件即可;如果是在spark集群上针对linux本地文件,那么需要将文件拷贝到所有worker节点上。
2、Spark的textFile()方法支持针对目录、压缩文件以及通配符进行RDD创建。
3、Spark默认会为hdfs文件的每一个block创建一个partition,但是也可以通过textFile()的第二个参数手动设置分区数量,只能比block数量多,不能比block数量少。
Spark-Spark RDD操作
Spark只支持两种RDD操作,transformation和action操作,transformation针对已有的RDD创建一个新的RDD文件,action主要是对RDD进行最后操作,比如遍历和reduce、保存到文件等,并可以返回结果到Driver程序
transformation,都具有lazy特性,只定义transformation操作是不会执行,只有接着执行一个action操作后才会执行。通过lazy特性避免产生过多中间结果。
wordcount程序就是如下执行流程,如下这块都在driver节点执行。所有transformation都是lazy,不会立即执行,只有执行了action后,才会触发job,提交task到spark集群上,进行实际的执行
transformation介绍
| 操作 | 介绍 |
|---|---|
| map | 将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
| filter | 对RDD中的元素进行判断,如果返回true则保留,返回false则剔除 |
| flatMap | 与map类似,但是对每个元素都可以返回一个或多个新元素 |
| groupByKey | 根据key进行分组,每个key对应一个Iterable |
| reduceByKey | 对每个key对应的value进行reduce操作 |
| sortByKey | 对每个key对应的value进行排序操作 |
| join | 对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理 |
| co'group | 同join,但是每个可以对应的Interable<value>都会传入自定义函数进行处理 |
action介绍
| 操作 | 介绍 |
|---|---|
| reduce | 将RDD元素进行聚合操作,第一个和第二个聚合,然后值与第三个依次类推 |
| collect | 将RDD中所有元素获取到本地客户端 |
| count | 获取RDD元素总数 |
| take(n) | 获取RDD前N个元素 |
| saveAsTextFile | 将RDD元素保存到文件中,对每个元素调用toString方法 |
| countByKey | 对每个Key进行count计数 |
| foreach | 对RDD中元素进行遍历 |
Spark-RDD持久化
多次对某个RDD进行transformation或者action,如果没有做RDD持久化,那么每次都要重新计算一个RDD,会消耗大量时间,降低Spark性能。
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。
巧妙使用RDD持久化,甚至在某些场景下,可以将spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清楚缓存,那么可以使用unpersist()方法。
Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
RDD持久化是可以手动选择不同的策略的。比如可以将RDD持久化在内存中、持久化到磁盘上、使用序列化的方式持久化,多持久化的数据进行多路复用。只要在调用persist()时传入对应的StorageLevel即可。
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算 |
| MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取 |
| MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。 |
| MEMORY_AND_DSK_SER | 同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上 |
| MEMORY_ONLY_2MEMORY_AND_DISK_2等等 | 如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。 |
如何选择RDD持久化策略?
Spark提供的多种持久化级别,主要是为了在CPU和内存消耗之间进行取舍。下面是一些通用的持久化级别的选择建议:
1、优先使用MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
2、如果MEMORY_ONLY策略,无法存储的下所有数据的话,那么使用MEMORY_ONLY_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化。
3、如果需要进行快速的失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
4、能不使用DISK相关的策略,就不用使用,有的时候,从磁盘读取数据,还不如重新计算一次。
不使用RDD持久化
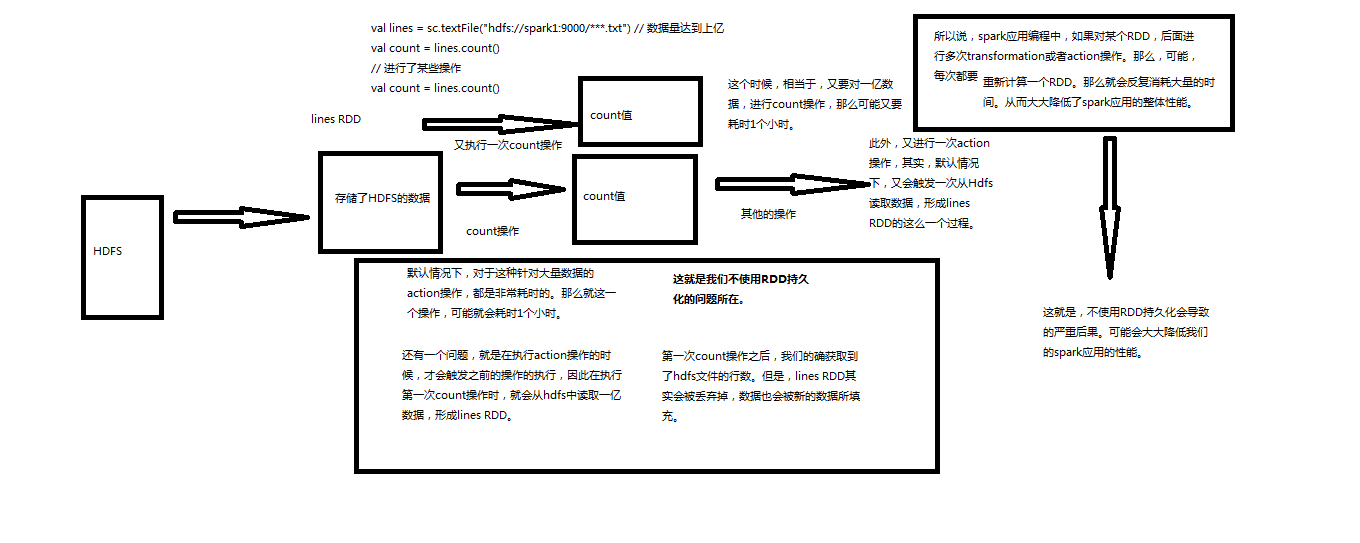
使用RDD持久化sc.textFile("E:\\spark\\spark.txt").cache();
RDD理解及宽依赖和窄依赖
名词解析
-
一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job。
-
stage : stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。Spark中Stage的划分就是通过shuffle来划分。
-
task :即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个partition,就会有多少个 task,因为每一个 task 只是处理一个partition 上的数据。
Stage的划分规则
-
从后向前推理,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到Stage中;
-
每个Stage里面的Task的数量是由该Stage中最后 一个RDD的Partition数量决定的;
-
最后一个Stage里面的任务的类型是ResultTask,前面所有其他Stage里面的任务类型都是ShuffleMapTask;
-
代表当前Stage的算子一定是该Stage的最后一个计算步骤;
总结:由于spark中stage的划分是根据shuffle来划分的,而宽依赖必然有shuffle过程,因此可以说spark是根据宽窄依赖来划分stage的。
Spark优化
流水线(pipeline)优化
变换算子序列一碰上shuffle类操作,宽依赖就发生了,流水线优化终止
在spark中pipeline是一个partition对应一个partition,所以在stage内部只有窄依赖,stage与stage之间是宽依赖
分布式计算过程
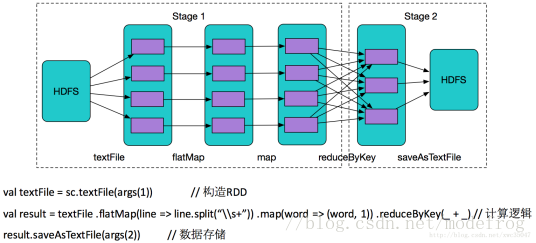
根据上述stage划分原则,这个job划分为2个stage,产生了一个宽依赖
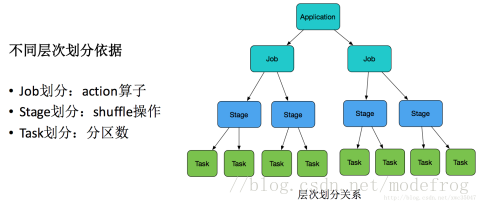
Application就是用户submit提交的整体代码,代码中又有很多action操作,action算子把Application划分为多个job,job根据宽依赖划分为不同Stage,Stage内划分为许多(数量由分区决定,一个分区的数据由一个task计算)功能相同的task,然后这些task提交给Executor进行计算执行,把结果返回给Driver汇总或存储。
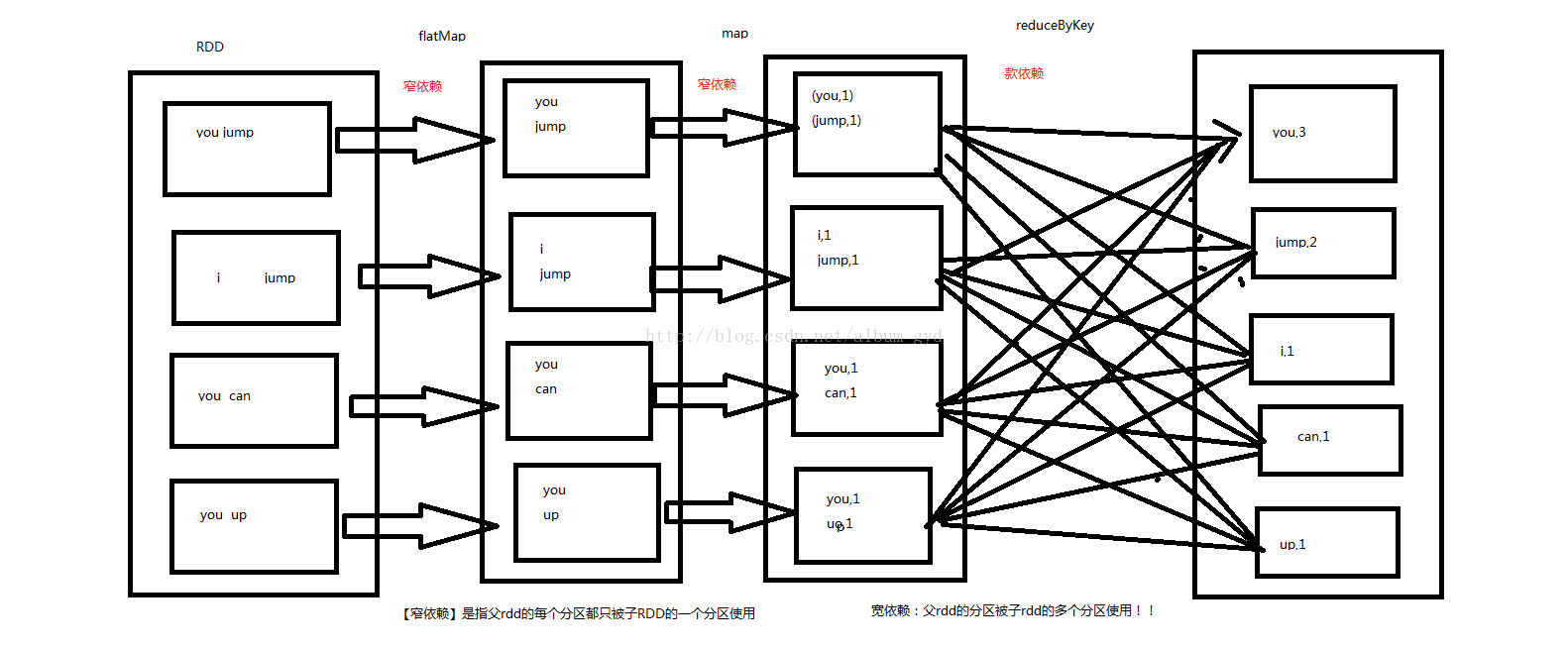
一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以相互依赖。如果RDD的每个分区最多只能被一个Child RDD的一个分区使用,则称之为narrow dependency;若多个Child RDD分区都可以依赖,则称之为wide dependency。
宽依赖:父RDD的分区被子RDD的多个分区使用 例如 groupByKey、reduceByKey、sortByKey等操作会产生宽依赖,会产生shuffle
窄依赖:父RDD的每个分区都只被子RDD的一个分区使用 例如map、filter、union等操作会产生窄依赖
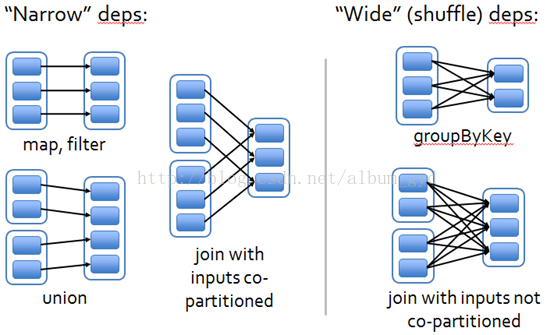
窄依赖
窄依赖是指1个父RDD分区对应1个子RDD的分区。换句话说,一个父RDD的分区对应于一个子RDD的分区,或者多个父RDD的分区对应于一个子RDD的分区。所以窄依赖又可以分为两种情况:
1个子RDD的分区对应于1个父RDD的分区,比如map,filter,union等算子
1个子RDD的分区对应于N个父RDD的分区,比如co-partioned join
宽依赖
宽依赖是指1个父RDD分区对应多个子RDD分区。宽依赖有分为两种情况
1个父RDD对应非全部多个子RDD分区,比如groupByKey,reduceByKey,sortByKey
1个父RDD对应所有子RDD分区,比如未经协同划分的join
join操作有两种情况:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputsco-partitioned);其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputsnot co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
Spark-共享变量工作原理
Spark一个非常重要的特性就是共享变量。
默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量副本。如果多个task想要共享某个变量,那么这种方式是做不到的。
Spark为此提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,更大的用处是优化性能,减少网络传输以及内存消耗。Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作。
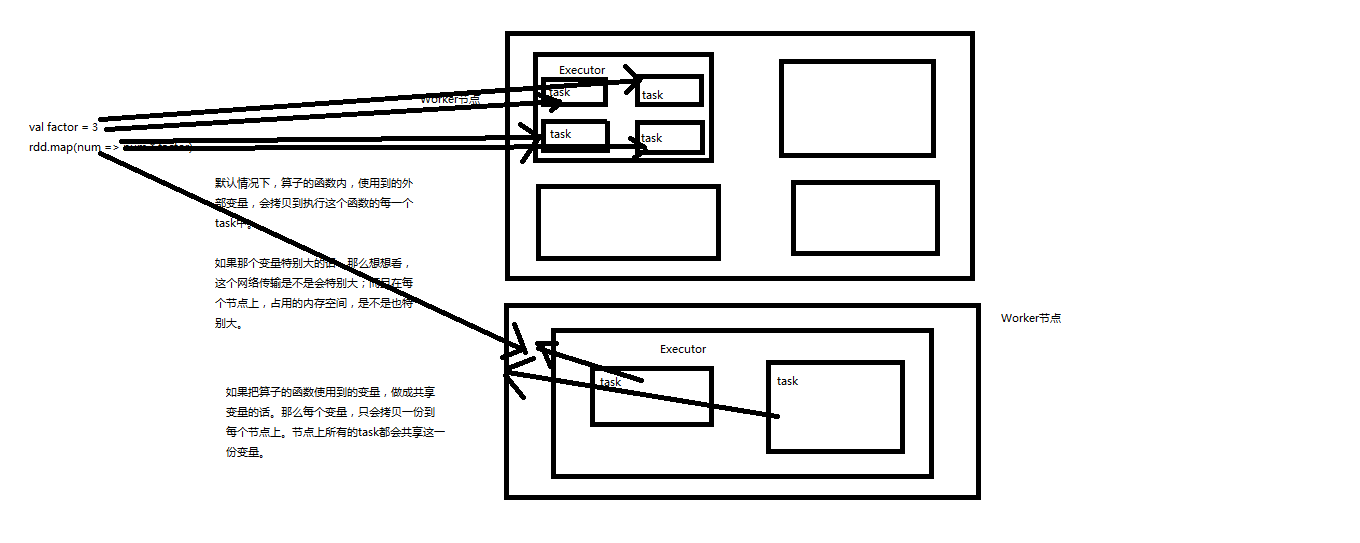
broadcast示例
package cn.spark.study.core;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast;
import java.util.Arrays;
import java.util.List;
public class BroadcastVariable {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("WordCountLocal")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
final int factor =3;
final Broadcast<Integer> factorBroadCast = sc.broadcast(factor);
List<Integer> numberlist = Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> numbers = sc.parallelize(numberlist);
JavaRDD<Integer> multipleNumbers = numbers.map(new Function<Integer, Integer>() {
private static final long serialVersionUID =1l;
@Override
public Integer call(Integer integer) throws Exception {
return integer * factorBroadCast.getValue();
}
});
multipleNumbers.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
System.out.println(integer);
}
});
sc.close();
}
}
package cn.spark.study.core
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastVariable{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Broadcast")
.setMaster("local")
val sparkContext = new SparkContext(conf)
val factor =3
val broadcast = sparkContext.broadcast(factor)
val numberArray = Array(1,2,3,4,5)
val numbers = sparkContext.parallelize(numberArray,1)
val multipleNumbers = numbers.map{num => num * broadcast.value}
multipleNumbers.foreach{num => println(num)}
}
}
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("PythonWordCount") \
.getOrCreate()
sc = spark.sparkContext
factor = 3
b_f = sc.broadcast(factor)
counts = sc.parallelize(range(1, 6)).map(lambda x: x * b_f.value)
output = counts.collect()
print(output)
spark.stop()
accumulator示例
package cn.spark.study.core;
import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import java.util.Arrays;
import java.util.List;
public class AccumulatorVariable {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("WordCountLocal")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
final Accumulator<Integer> accumulator = sc.accumulator(0);
List<Integer> numberlist = Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> numbers = sc.parallelize(numberlist);
numbers.foreach(new VoidFunction<Integer>() {
@Override
public void call(Integer integer) throws Exception {
accumulator.add(integer);
}
});
System.out.println(accumulator);
sc.close();
}
}
package cn.spark.study.core
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorVariable {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Broadcast")
.setMaster("local")
val sparkContext = new SparkContext(conf)
val sum = sparkContext.accumulator(0)
val numberArray = Array(1,2,3,4,5)
val numbers = sparkContext.parallelize(numberArray,1)
numbers.foreach{sum +=_}
println(sum)
}
}